















Россия
УДК 696.117 Краны. Запорные задвижки. Вентили. Прочая арматура
Введение. Корни современной предиктивной аналитики уходят в далекие 1940-е годы, когда правительства начали использовать первые вычислительные модели: метод Монте-Карло, вычислительные модели нейронных сетей и линейное программирование. В 1960-х годах корпорации и исследовательские институты начали эпоху коммерциализации аналитики с помощью компьютерной техники. Затем в 1970-х — 1990-х годах получила большее распространение в организациях. Технологические стартапы сделали реальными предписывающую аналитику (Prescriptive analytics) и анализ в режиме реального времени. Материалы и методы. Использованы данные из открытых источников. Предметом исследования является история, современное состояние систем предиктивной аналитики и перспективы разрабатываемой методики анализа больших данных с целью предсказания изменения этапов жизненного цикла элементов инженерного оборудования зданий и сооружений. Подготовка и визуализация информации выполнялась при помощи Microsoft Office Excel. Результаты. Исследованы термины, история появления, развития и современное состояние систем предиктивной аналитики. Изучены перспективы, разрабатываемой в диссертационной работе, методика анализа больших данных с целью предсказания изменения этапов жизненного цикла элементов инженерного оборудования зданий и сооружений. Использование в диссертационной работе «Контрольных карт Шухарта», методов кластерного и квалиметрического анализа в несвойственных для них сценариях, позволяет рассчитывать на положительные перспективы разрабатываемой методики. Выводы. Предиктивная аналитика в строительной области является одним из наиболее перспективных направлений анализа больших данных. Разрабатываемая в диссертационной работе методика анализа больших данных с целью предсказания изменения этапов жизненного цикла элементов инженерного оборудования зданий и сооружений основана на использовании современных алгоритмов. Научная новизна состоит в подходе к анализу, в котором используется комбинированная схема, в которой кластерный и квалиметрический методы анализа используются для поиска элементов оборудования близких к изменению этапа жизненного цикла.
большие данные, предиктивная аналитика, жизненный цикл, инженерное оборудование, интеллектуальный анализ данных, кластерный анализ, квалиметрия, фазы жизненного цикла, системы прогнозирования, контрольные карты Шухарта
Введение
Корни современной предиктивной аналитики уходят в далекие 1940-е годы, когда правительства начали использовать первые вычислительные модели: метод Монте-Карло, вычислительные модели нейронных сетей и линейное программирование. Это применялось для расшифровки немецких сообщений во время Второй мировой войны, самонаведения орудий ПВО и прогнозного моделирования ядерных цепных реакций в проекте «Манхэттен». В 1960-х годах корпорации и исследовательские институты начали эпоху коммерциализации аналитики с помощью нелинейного программирования и решения эвристических задач на основе компьютеров. Это легло в основу первых моделей прогноза погоды, решения «задачи кратчайшей пути» для авиаперевозок и логистики, а также предиктивного моделирования для принятия решений о кредитном риске. Затем в 1970-х — 1990-х годах получила большее распространение в организациях. Технологические стартапы сделали реальными предписывающую аналитику (Prescriptive analytics) и анализ в режиме реального времени. Тем не менее, предиктивная аналитика была инструментом, в первую очередь для специалистов по статистике и доходила до бизнес-пользователей только в виде статичных отчетов [1]. Сегодня предиктивная аналитика стала одним из важных направлений корпоративной аналитики, которая используется для решения широкого круга задач. Этот тренд обусловлен реалиями мировой экономики: организации постоянно ищут конкурентные преимущества и внедряют новые технологии.
Материалы и методы
Предиктивная аналитика — это процесс использования статистических моделей, алгоритмов машинного обучения и других методов анализа данных для прогнозирования будущих событий и поведения на основе исторических данных. В качестве примера рассмотрим несколько методик, используемых в области предиктивной аналитики:
1. Регрессионный анализ: Этот метод предсказывает значения зависимой переменной на основе набора независимых переменных. Это позволяет определить, какие факторы влияют на конкретное явление и какую роль они играют.
2. Кластерный анализ: Этот метод помогает группировать схожие объекты или события. Например, компания может использовать кластерный анализ для идентификации сегментов клиентов с похожим поведением или характеристиками, чтобы лучше понять их потребности и предоставить персонализированный опыт.
3. Классификация и прогнозирование: Данный метод используется для определения категории или класса, к которому может принадлежать объект или событие. Например, система мошеннического обнаружения может использовать классификацию для определения, является ли транзакция подозрительной или нет.
4. Временные ряды: Этот метод предсказывает будущие значения какой-либо переменной на основе ее исторических значений. Он используется для анализа временных данных, таких как прогнозирование продаж, предсказание цен на фондовом рынке или прогнозирование погоды.
5. Машинное обучение: Этот подход использует алгоритмы и модели машинного обучения для предсказания будущих результатов. Он может быть применен в различных сферах, от медицины до рекламы, чтобы прогнозировать, например, будущие заболевания пациентов или предложить наиболее релевантную рекламу на основе предпочтений пользователя.
6. Оптимизация ресурсов: Эта область предиктивной аналитики используется для оптимизации распределения ресурсов, таких как прогнозирование спроса на товары и услуги, планирование производства, оптимизация логистики или управление запасами.
Это лишь несколько примеров видов предиктивной аналитики. Все они имеют цель предсказывать будущие события и результаты на основе анализа исторических данных. Они могут быть применены в различных областях, от бизнеса до медицины, чтобы помочь принимать более информированные решения и лучше понимать будущие тенденции и потребности [2-3].
В качестве примера рассмотрим методику анализа больших данных с целью предсказания изменения этапов жизненного цикла элементов инженерного оборудования зданий и сооружений, которая, в итоге, направлена на снижение издержек при проектировании и реализации систем инженерного оборудования зданий за счёт отказа от многоуровневого дублирования, упрощение работы обслуживающего персонала снижения аварийности в процессе эксплуатации зданий и сооружений. Данное исследование является развитием идей, представленных автором в следующих статьях: «Predicting the Elements Operation of Buildings’ Engineering Equipment Using the Big Data Analysis Technologies» [4] и «Разработка методики анализа больших данных с целью предсказания изменения фаз жизненного цикла элементов инженерного оборудования зданий и сооружений» [5]. Конечной целью исследования является создание полнофункционального приложения, готового к реальной эксплуатации.
Алгоритм работы приложения:
Внешние данные поступают в логический блок, где проверяется, является ли изделие работающим? Если оно работает, передаём данные в блок прогнозирования. Если устройство не работает, снимаем дампы данных и передаём в следующий логический блок, где с использованием метода «Контрольных карт Шухарта» определяется является ли вышедшее изделие браком [6]. Если устройство вышло из строя штатно, данные передаются в модуль перерасчёта «Эталонной модели стандартной» с использованием метода «Кластерного анализа» [7]. Данные, полученные от работающего изделия, обрабатываются методом «Квалиметрического анализа» с эталоном, полученным в блоке «Эталонная модель стандартная» [8]. Если полученные данные приближаются к эталонной модели, выдаётся рекомендация на проверку состояния устройства, в противном случае никаких действий не предпринимается. Если устройство вышло из строя с показателями, находящимися в области «Брака», данные передаются в модуль перерасчёта «Эталонной модели брак» с использованием метода «Кластерного анализа». Данные, полученные от работающего изделия, обрабатываются методом «Квалиметрического анализа» с эталоном, полученным в блоке «Эталонная модель брак». Если полученные данные приближаются к эталонной модели выдаётся первоочередная рекомендация на проверку состояния устройства, в противном случае никаких действий не предпринимается (Рис.1).
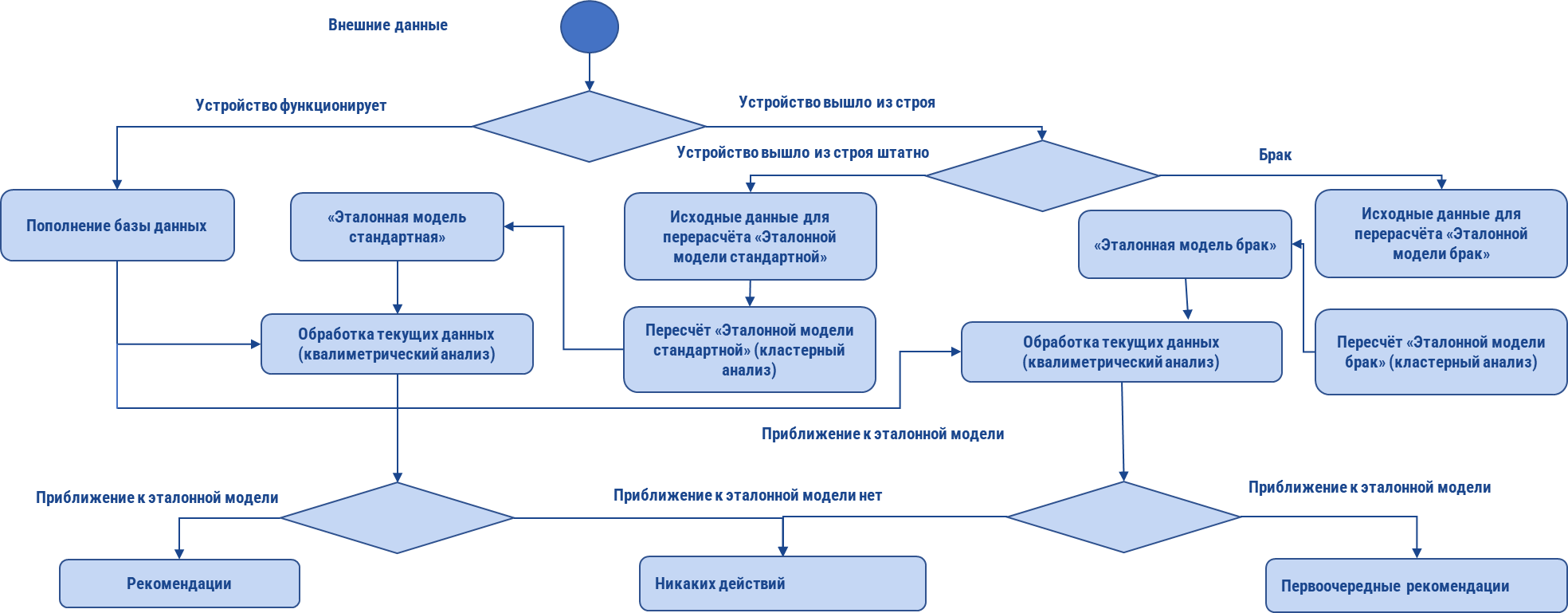
Рис.1. Алгоритм работы приложения
Результаты исследования
Расчёты производились на массиве данных, сгенерированном для проверки работоспособности математической модели в приложении Microsoft Excel [9-10]. Каждый объект описывается набором своих характеристик, называемых параметрами. Параметры могут быть числовыми или нечисловыми. Исходные данные на первоначальном этапе фильтруются с использованием экспертного метода и контрольных карт Шухарта (Рис.2.) Для построения карт были выбраны следующие параметры: наработка часов фактическая, количество включений, количество пропущенной воды. Для построения CL — центральной линии использовали среднее геометрическое значение па`раметров:
где $\overline{t}$ среднее геометрическое, n число показателей, а
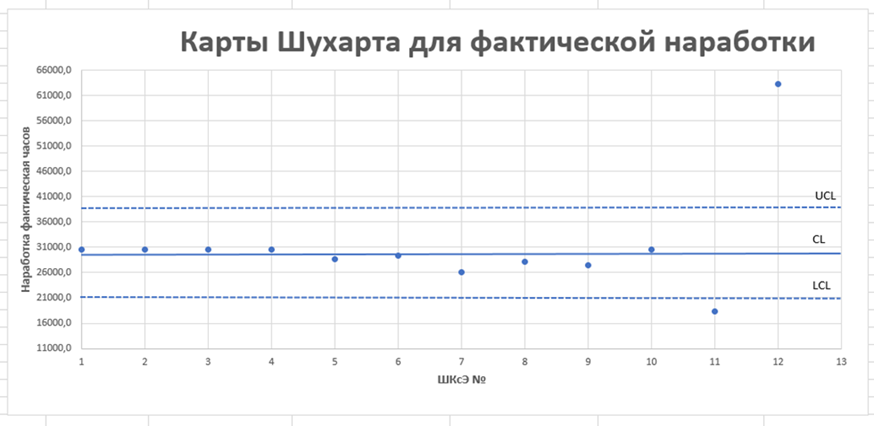
Рис.2. Контрольные карты Шухарта
С целью приведения параметров к сопоставимым величинам перед началом анализа используется метод нормализации данных (Рис. 3):
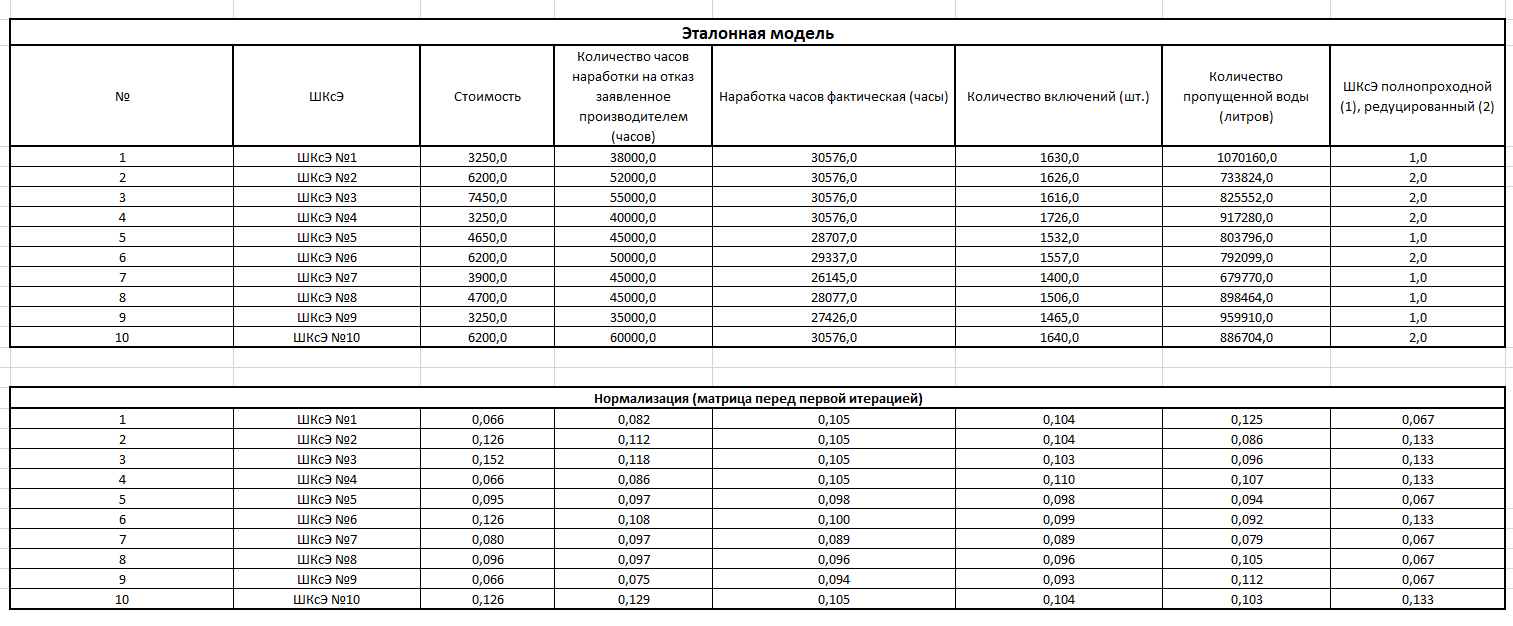
Рис. 3. Нормализация данных
Расчёт производится по следующей формуле:
$t_j=\frac{t_i}{\sum_{i=1}^nt_i}$ (2)
где
$\sum_{i=1}^nt_i– сумма исходных значений параметра t, нуждающегося в нормализации
Для поиска расстояний между объектами в матрице несходства использовалась формула нахождения евклидова расстояния:
где d (X, Y) - евклидово расстояние,
m - количество параметров у сравниваемых объектов,
Xi, Yi – значения параметров [11].
На первом этапе квалиметрического анализа рассчитывается процент ошибки на основании данных из эталонной модели кластерного анализа и показателей:
$q%=|t_Э-\frac{\overline{t}}{t_Э}|$, (4)
где q% – величина ошибки в процентах,
i=1…n – диапазон текущих параметров,
где t значение параметра для соответствующего устройства.
Параллельно указывается величина ошибки, полученная экспертным методом и все вычисления идут параллельно.
На втором этапе квалиметрического анализа нормализуем данные для анализа, используя следующие формулы:
1. Отклонение от эталонного значения параметра (
где
2. Интегральный показатель качества (Qинт):
где
q% – величина ошибки в процентах.
На завершающем этапе квалиметрического анализа находим среднее значение по объектам, сортируем их по возрастанию, вычисляем интервалы в полученной последовательности и находим среднее геометрическое интервалов. На основании вычисленной среднегеометрической делим получившуюся последовательность на кластеры (Рис. 4).
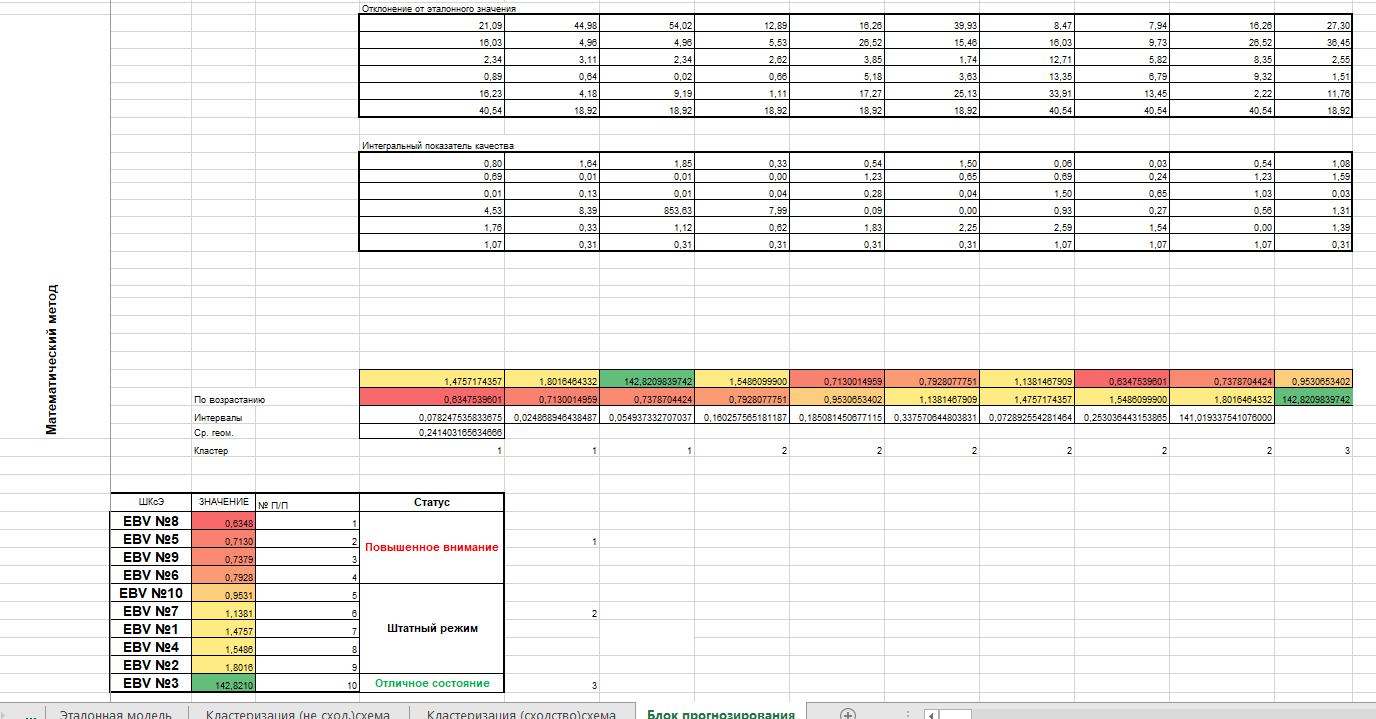
Рис. 4. Кластеризация для задач прогноза
Объединив результаты вычислений, полученных с использованием математического и экспертного методов, получаем итоговую таблицу с прогнозом (Рис. 5) [12].
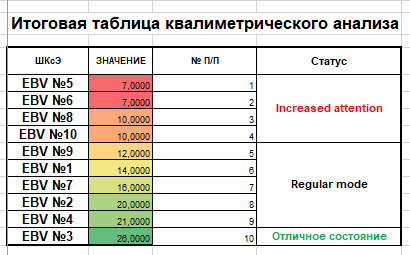
Рис. 5. Итоговая диаграмма прогноза
Заключение и обсуждение
Предиктивная аналитика является мощным инструментом для улучшения процессов и операций в строительной отрасли. Она позволяет строительным компаниям более точно прогнозировать спрос, оптимизировать ресурсы, управлять рисками, улучшать качество и повышать общую эффективность.
Методика анализа больших данных с целью предсказания изменения этапов жизненного цикла элементов инженерного оборудования зданий и сооружений основана на использовании современных алгоритмов предиктивной аналитики.
В качестве примера можно привести алгоритмы машинного обучения RFR (Random Forest Regressor), GBC (Gradient Busting Classifier) и GBR (Gradient Busting Regressor) описанные М.Р. Салиховым и Р.А. Юрьевой в статье «Алгоритм прогнозирования состояния оборудования на основе машинного обучения» [13].
Научная новизна состоит в подходе к анализу, в котором в отличие от классических схем, где кластерный и квалиметрический методы анализа используются для поиска наилучшего управленческого решения, в данной работе целью анализа, является поиск элементов оборудования близких к изменению фазы жизненного цикла.
На сегодняшний день исследование находится в активной фазе тестирования методики расчётов. Конечным результатом проведённого исследования будет являться полнофункциональный, гибкий программный комплекс, готовый к использованию как для предприятия, от которого получены исходные данные, так и для любого предприятия строительной сферы, с целью увеличения эффективности обслуживания элементов инженерного оборудования.
1. Першина Э.С., Дагаран С.В. От больших данных к продвинутой аналитике в индустрии туризма // Научный вестник МГИИТ. - Номер: 2 (52), 2018. - С: 60-69.
2. Kagan P. Big data sets in construction. E3S Web Conf., International Science Conference SPbWOSCE-2018 “Business Technologies for Sustainable Urban Development”. 2019, Volume 110, Number 3, pages: 80-84, doihttps://doi.org/10.1088/1757-899X/869/2/022004 EDN: https://elibrary.ru/LKXHMP
3. Прокопец А. Конкурентное программирование на Scala. - М.: ДМК-Пресс, 2018. - 342 с.
4. Kagan P., Sigitov A. Predicting the Elements Operation of Buildings’ Engineering Equipment Using the Big Data Analysis Technologies // Lecture Notes in Civil Engineering, 2022, 231, стр. 87-93. DOI:https://doi.org/10.1007/978-3-030-96206-7_9 EDN: https://elibrary.ru/UVZAOR
5. Сигитов А.А. Разработка методики анализа больших данных с целью предсказания изменения фаз жизненного цикла элементов инженерного оборудования зданий и сооружений // Строительство и архитектура. - Т. 11 № 2 (39). - DOI https://doi.org/10.29039/2308-0191-2023-11-2-8-8 EDN: https://elibrary.ru/OTWJEE
6. Дорофеев М. Практикум использования контрольных карт Шухарта // Электронный журнал Хабр. - 07.03.2012. [Электронный ресурс] - URL: https://habr.com/ru/post/139596/ (дата обращения: апрель 2022).
7. Kagan P. The use of digital technologies in building organizational and technological design // E3S Web Conf. 2021, Vol. 263, XXIV International Scientific Conference “Construction the Formation of Living Environment” (FORM-2021), Article Number 04040. - https://doi.org/10.1051/e3sconf/202126304040 EDN: https://elibrary.ru/NDEWOE
8. Лескова Ю.Г. Применение информационных (цифровых) технологий в саморегулировании как условие развития строительной отрасли и правовое регулирование // Гражданское право. - Т. 5., 2018. - С. 9-11. - DOI:https://doi.org/10.18572/2070-2140-2018-5-9-11. EDN: https://elibrary.ru/XZCIHR
9. Форман Д. Много чисел: анализ больших данных с помощью Excel. - М.: Альпина Паблишер, 2016. - 464 с.
10. Прокопец А. Конкурентное программирование на Scala ДМК-Пресс. - М., 2018. - 342 с.
11. Дюран Б., Одель П. Кластерный анализ. - М.: Статистика, 1977)
12. Азгальдов Г.Г., Азгальдова Л.А., Количественная оценка качества (Квалиметрия). - М.: Издательство стандартов, 1971, 176 с. EDN: https://elibrary.ru/NSBLCW
13. Салихов М.Р., Юрьева Р.А., Алгоритм прогнозирования состояния оборудования на основе машинного обучения // Изв. Вузов. Приборостроение. - Т. 65, №9, 2022. - С. 648-655. - DOI:https://doi.org/10.17586/0021-3454-2022-65-9-648-655 EDN: https://elibrary.ru/FBHJVU
