














Russian Federation
Russian Federation
UDC 62
UDC 681.5
UDC 004.94
The article discusses the relevance of deep learning methods using in predictive analytics of parameters of engineering systems in construction. The advantages and disadvantages of such methods are described, as well as the architecture of a cyberphysical type system based on machine learning for solving the problem of predictive analytics algorithms for building engineering system parameters. Conclusions are drawn about the applicability of the DBSCAN clustering algorithms, neural networks with the Attention mechanism and hierarchical trees ensembles within the research task.
digital twin, cyberphysical system, machine learning, neural networks, smart home, smart house, automated systems, predictive analytics, engineering systems, life cycle
Введение
Благодаря развитию глобальных цифровых технологий автоматизация инженерных систем в строительной отрасли стала неотъемлемой частью жизненного цикла любого здания или сооружения. Общеизвестная концепция Smart House представляющая собой концепцию "умного дома", предполагает создание комфортного и безопасного пространства для жизни и работы людей при помощи автоматизированных инженерных систем. Работа подобных систем в современных реалиях требует не только базового поддержания заданных пользователем параметров но и внедрение предиктивной аналитики, которая, на разных этапах жизненного цикла здания помогает решить сразу ряд задач, среди которых: мониторинг компонентов систем и предупреждение возникновения аварий, предугадывание событий и предварительная реакция на них, построение аналитики для возможности прогнозировать поломки / расходы и прочие задачи. Для решения всех вышеперечисленных задач в более ранних статьях [1, 2] была предложена архитектура системы киберфизического типа на основе машинного обучения (рис. 1 [1]). Предполагается, что подобная система сможет функционировать на основе событий, возникающих в процессе эксплуатации зданий под действием внешних и внутренних факторов. Под событиями в данном случае следует принимать совокупность полученных от АС наборов физических параметров (температура, влажность, давление, напряжение и др.) с меткой времени. В качестве примера событий из реального мира можно представить: смену погодных условий и изменение естественного освещения, совещание в небольшом помещении на большое количество людей, специальные температурные режимы для разных типов работ, увеличение нагрузки на систему водопровода в жилых домах в связи с возвращением людей домой после рабочего дня и прочее. Каждое событие в таком случае может иметь свой набор граничных значений для каждого из физических параметров, что позволит системе настраивать более тонкую реакцию на изменения состояния автоматизированных систем и контролировать их поведение при помощи различных алгоритмов машинного обучение [3]. Также предполагается, что подобная система сможет расширяться под нужды пользователей и при необходимости дополняться дополнительными модулями под определенные прикладные задачи. Данное решение позволит эффективнее и более точно производить аналитику полученных внешних данных, а следовательно, и их контроль за счет использования наиболее подходящих алгоритмов обработки данных и возможности добавления специфики прикладной области [4].
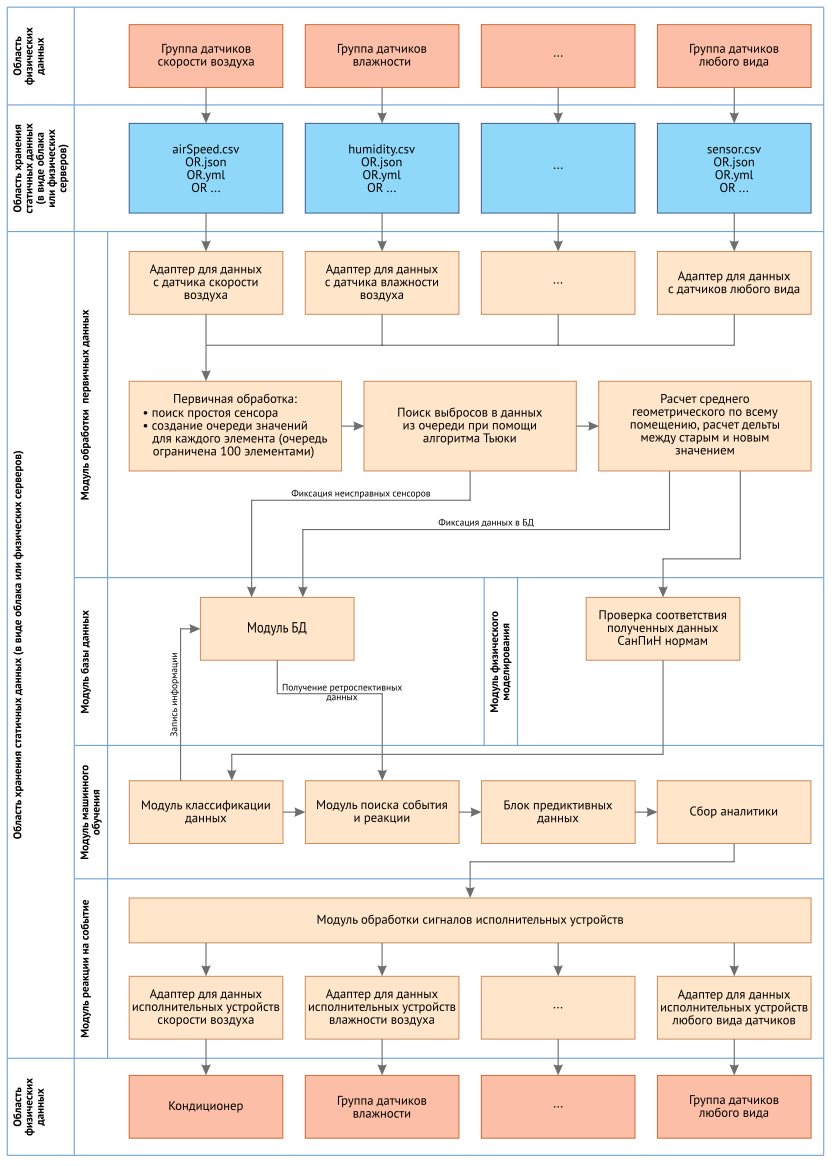
Рис. 1. Диаграмма деятельности (процессов) UML
Описание алгоритмов
Система получает данные с различных сенсоров и датчиков, после чего полученные физические данные в режиме реального времени перед применением машинного обучения проходят предварительную обработку, включая фильтрацию и исключение «выборосов» в данных, нормализацию и преобразование категориальных признаков в числовые значения [5]. Следующим этапом является расчёт вторичных данных, а именно статистической информации для каждого параметра на определенном временном срезе, она включает в себя: средние значения (среднее математическое, среднее геометрическое) и динамику (градиент). На основе вычисленных данных система производит проверку по занесенным в систему границам значений из нормативных документов каждой конкретной прикладной области. Для уменьшения количества рабочих данных последующие шаги, включающие в себя алгоритмы обработки работают на основе полученных вторичных данных. Весь ранее описанный процесс можно проиллюстрировать следующим изображением (рис. 2 [1]):

Рис. 2. Последовательность состояний данных в системе
Для поиска событий и нахождения принадлежности среза параметров с определенной временной меткой к одному из событий предлагается использовать алгоритмы кластеризации (алгоритмы классификации, которые подразумевают участие учителя не рассматриваются в связи с возможным объёмом количества событий и требованием к возможности самокалибровки системы без участия человека). При решении этой задачи категоризации также следует учитывать необходимость или отсутствие необходимости передачи дополнительной информации [6], в частности, по этому принципу предлагается отсеять все алгоритмы, требующие в качестве входных параметров количество кластеров, так как эта информация заранее не может быть известна. Всем указанным ранее условиям удовлетворяет DBSCAN (Density-Based Spatial Clustering of Applications with Noise, плотностной алгоритм пространственной кластеризации с присутствием шума). Метод не требует предварительных предположений о числе кластеров, но требует настроить два других параметра: eps и min_samples. Данные параметры – это соответственно максимальное расстояние между соседними точками и минимальное число точек в окрестности (количество соседей), когда можно говорить, что эти экземпляры данных образуют один кластер. Важно отметить, что от одного набора параметров к другому, алгоритм требует точечной настройки для повышения эффективности.
После разбиения данных на события (или кластера), с заданной периодичностью данные каждой подсистемы проходят через обработку алгоритмом машинного обучение для предиктивной аналитики и расчета вероятностей совершения будущих событий во времени. В данном случае к аналитическим алгоритмам можно применить следующий набор требований: возможность алгоритма на основе исторических данных предсказывать будущие данные, возможность работы с большими данными (требования скорости), скорость обучения и дообучения (для систем, где необходима высокая скорость смены состояний и скорости реакции на такие изменения) [7], возможность работы сразу с набором параметров, а не единичным параметром, требования надёжности и устойчивости к возможным выбросам (несмотря на предварительные шаги по их исключению, возможность выбросов остается). В результате анализа существующих алгоритмов по заданным условиям предлагается использование следующих алгоритмов (данные алгоритмы планируется включить в базовый набор алгоритмов предсказательной аналитики системы): нейронная сеть со слоем Attention (внимание) и алгоритм случайного леса.
Использование нейронных сетей стало своеобразным стандартом в задачах стоящих перед алгоритмами машинного обучения. В данном случае предполагается использование нейронных сетей с механизмом Attention для решения проблемы временных рядов (прогнозирования будущих событий и предиктивная реакция). Механизм Attention является более эффективным вариантом обработки данных чем LSTM (Long-short term memory) и RNN (рекуррентные нейронные сети). Достигается это за счет уменьшения количества требуемых на обучение и работу ресурсов, так как данным не требуется проходить через всю последовательность ячеек, в то время как Attention требует меньшее количество слоев. В своей работе данный механизм формирует матрицу весов важности, по которой определяется функция вероятности для поступивших на вход сети данных. Ориентировочная сложность подобного алгоритма является O(n2*d), где n - длинна последовательности, а d - глубина (количество слоев). Данный алгоритм по отношению к обычным нейронным сетям дает преимущество в использовании оперативной памяти за счет механизма Attention. Важно уточнить, что перед внедрением в систему алгоритм должен пройти апробацию на предмет точности, данный аспект будет предметом дальнейших исследований.
Алгоритм случайного леса предполагается использовать как альтернатива нейронным сетям. Данным методом можно решать задачи регрессии в случае предсказания непрерывной переменной или задачи классификации для категориальных переменных [8]. Суть метода заключается в том, что каждому дереву в ансамбле назначается набор наблюдений, который состоит из определенного количества признаков. Каждое дерево получает не все признаки для предсказания, а только некоторое количество, которое равно квадратному корню из общего числа признаков. Таким образом, каждый отдельный узел дает классификацию не самого высокого качества, но благодаря большому числу узлов итоговый результат получается достаточно точным. Итоговая оценка осуществляется обычным голосованием узлов, класс определяется по большинству голосов из ансамбля. Ориентировочная сложность этого алгоритма O(v*n log(n)), где n - длинна последовательности, а v — количество атрибутов (переменных). Данный алгоритм имеет меньшую сложность, чем предыдущий, но требователен к ресурсам на этапе обучения. Аналогично предыдущему, рассматриваемый алгоритм также должен пройти апробацию для получения информации по его применимости в решении искомой задачи.
Как было указано ранее, также в системе предполагается возможность добавления пользовательских алгоритмов для решения специфичных для конкретной проектной области задач, так как ни одним предсказательным алгоритмом невозможно закрыть все возможные задачи и проанализировать все события.
Методы глубокого обучения, такие как нейронные сети или деревья, способны обрабатывать большие объемы данных и извлекать из них ценную информацию. Однако, они требуют большого количества вычислительных ресурсов и времени на обучение [9]. В то же время, статистические методы, такие как регрессионный анализ, могут быть использованы для оценки влияния различных факторов на параметры системы [10]. При выборе метода предиктивной аналитики необходимо учитывать особенности задачи, объем данных, скорость обработки информации и другие факторы.
Рассмотрим несколько примеров применимости предлагаемой киберфизической системы управляющей АС зданий и сооружений в процессе их жизненного цикла.
- Управление микроклиматическими параметрами, включающими в себя контроль температуры, влажности, ионизации воздуха, количества CO2 и прочими параметрами, в случае, с типичными системами умного дома, замеряемые параметры зачастую анализируются отдельно друг от друга, что может приводить к нерациональному использованию агрегатов, управляющих микроклиматом. Также типичные системы поддерживают только базовую автоматизацию (поддержание параметров на заданном уровне и использование расписание работы агрегатов) [11], тогда как предлагаемая концепция сделает систему саморегулируемой и не зависящей от человека. Это, например, позволит заранее подготавливать помещение перед совещаниями, в зависимости от внешних условий включать / выключать климатические системы и прочее.
- Возможность использования в системах водоснабжения для своевременного обнаружения возможных неполадок, износа оборудования и планирование ремонтов на основе полученных данных.
- Возможность автоматического управления освещением и построения интеллектуального сценария, учитывающего расписание, виды работ в определенное время в определенных помещениях.
Заключение
В данной статье были предложены и проанализированы алгоритмы предиктивной аналитики в решении задачи контроля параметров инженерных систем. Результатом исследования стало описание подготовки данных, кластеризации данных по определенным признакам и решение задачи анализа временных рядов для предсказания и предиктивной реакции на будущие события.
1. Losev K.Yu., Krestelev D.I. Automated Engineering System Architecture to the Determining Events Technique during the Operation of Buildings and Structures [Architektura avtomatizirovannoy inzhenernoy systemy dlya metodiki opredeleniya sobytiy pri ekspluatasii zdaniy i sooryzheniy] // Construction production. - 2022. - Vol/ 4. - p. 65-72. DOI:https://doi.org/10.54950/26585340_2022_4_65 (In Russian). EDN: https://elibrary.ru/MZHDFF
2. Krestelev D.I. Statement of the problem of microclimate control in a design office [Postanovka zadachi kontrolya mikroklimata v proektnom byuro] / Days of Student Science [Electronic resource]: collection of reports of a scientific and technical conference based on the results of research work of students of the Institute of Economics, Management and Information Systems in Construction and Real Estate NRU MGSU (Moscow, 1-5 March 2021) (In Russian) EDN: https://elibrary.ru/VFNEQM
3. Evmenov, V.P. Intelligent control systems: superiority of artificial intelligence over natural intelligence? [Intellektual'nye sistemy upravleniya: prevoskhodstvo iskusstvennogo intellekta nad estestvennym intellektom?] / V.P. Evmenov. - M.: KD Librocom, 2016. - 304 p (In Russian).
4. Kim, D.P. Theory of automatic control. P. 2. Multidimensional, nonlinear, optimal and adaptive systems [Teoriya avtomaticheskogo upravleniya. T. 2. Mnogomernye, nelinejnye, optimal'nye i adaptivnye sistemy] / D.P. Kim. - M.: Fizmatlit, 2007. - p. 440. EDN: https://elibrary.ru/QMROVT
5. Xueyi Liu, Chuanhou Gao, Ping Li. A comparative analysis of support vector machines and extreme learning machines // Neural Networks. - 2012. - vol. 33. - p. 58-66.
6. Trevor Hastie, Robert Tibshirani, Jerome Friedman. The elements of statistical learning: Data mining, inference and prediction. / New York: Springer-Verlag - 2001. - p. 35-40
7. Domingos, Pedro The Supreme Algorithm: How Machine Learning Will Change Our World [Verhovnyj algoritm: kak mashinnoe obuchenie izmenit nash mir] / Pedro Domingos. - Moscow: Russian State University for the Humanities, 2015. - 447 p (In Russian).
8. Breiman, L. Random Forests. // Machine Learning. - 2001. - vol. 45. - p. 5-32. doi:https://doi.org/10.1023/A:1010933404324. EDN: https://elibrary.ru/ARROTH
9. Churakov, E.P. Introduction to multivariate statistical methods [Vvedenie v mnogomernye statisticheskie metody]: Textbook / E.P. Churakov. - St. Petersburg: Lan, 2016. - p. 148 (In Russian).
10. Shiryaev, A.N. Probabilistic-statistical methods in decision-making theory [Veroyatnostno-statisticheskie metody v teorii prinyatiya reshenij] / A.N. Shiryaev. - M.: MTsNMO, 2014. - p. 144.
11. Puchenkov I.S., Evtushenko S.I. Creating an information model of a building in a shared data environment [Sozdanie informacionnoj modeli zdaniya v srede obstchich dannych] // Construction and architecture. - 2021
