









Пенза, Пензенская область, Россия
Пензенская область, Россия
Серьезный научный интерес для аналитиков представляют открытые социальные данные сети Интернет. Однако эти данные не пригодны для автоматизированной прикладной обработки в исходном состоянии и должны быть представлены в структурированном, понятным при ручной обработке виде – социальном профиле. Построение социального профиля осуществляется через анализ отфильтрованных исходных данных из открытых источников сети Интернет. Динамические неструктурированные данные, включающие в себя как текстовую, так и мультимедиа информацию, не могут быть исследованы классическими средствами аналитики. Следовательно, требуется определить новые аналитические методы и подходы, зависящие от вида обрабатываемых данных, для наиболее эффективного использования исходных данных. Задача анализа данных социального профиля достигается за счет использования математического аппарата теории множеств, программных комплексов Big Data, средств аналитики социальных медиа, а также современных методов анализа мультимедиа. В статье предложены методы анализа неструктурированной текстовой информации социального профиля. Описывается технология поиска неявных зависимостей в текстах с использованием средств визуального анализа и обработки естественного языка. Также предлагается обзор методик для анализа мультимедиа контента (графика, звук). Этап анализа разнородных данных социального профиля является достаточно сложным в реализации. Существует возможность частично автоматизировать процесс анализа информации за счет использования средств визуального анализа, обработки естественного языка (NLP), нейронных сетей и специализированных алгоритмов. Полученные данные обеспечивают подробный детальный обзор связей и сущностей социального профиля и могут использоваться в дальнейших более глубоких социальных исследованиях.
Анализ данных, неструктурированные данные, мультимедиа, открытые источники информации, социальный профиль человека, Big Data.
Введение НЕТ СПИСКА ЛИТЕРАТУРЫ
Социальный профиль – это множество информации, характеризующее социальные свойства человека и наглядно структурированное для удобства автоматизированной обработки и человеческого восприятия [1]. Социальные профили могут найти свое применение в различных сферах деятельности, начиная с прикладных целей контекстной передачи информации и заканчивая исследованиями искусственного интеллекта и социума, а также противодействия терроризму.
Задача построения социального профиля первоначально сводится к созданию математической модели и выбору структуры данных для хранения персонализированной информации [2]. Социальный профиль человека основывается на данных из открытых источников сети Интернет. Идентификация человека в сети производится через определение его точек вхождения – учетных записей веб-ресурсов, которые предоставляют ему ряд возможностей по использованию ресурса и выделяют из массы остальных пользователей сети. Собираемые данные фильтруются от посторонней информации и разделяются по степени структурированности на статическую и динамическую части. С учетом экспоненциального роста информации в сети перед аналитиками стоит задача автоматизировать процессы анализа как структурированной, так и неструктурированной информации. В данной работе освещаются проблемы анализа текстовых и мультимедийных данных социального профиля человека с использованием различных средств (Big Data, OCR, визуальный анализ, статистика и т.д.).
После идентификации человека в сети Интернет, сбора и фильтрации первичных данных социального профиля [2, 3] полученная информация анаизируется с целью формирования целостной структурированной социальной картины личности. Собранная ранее информация разделяется на две логические части [2]: информационную карту, содержащую уникальные идентифицирующие сведения о рассматриваемой персоне - статический контент, и динамический контент, состоящий из гетерогенных неструктурированных данных. Эти данные хранятся в различных типах хранилищ, зависящих от характера самой информации. Для хранения данных, не предусматривающих редактирования, предлагается использовать HBase - нереляционную распределенную базу данных с открытым исходным кодом, которая запускается над распределенной файловой системой HDFS (Hadoop Distributed File System) и обеспечивает надежный способ хранения очень больших объемов разнородных данных [4].
Соответствующая геоинформация помещается в графовое хранилище Neo4J [5], основными характеристиками которого являются: поддержка ACID (англ. Atomicity, Consistency, Isolation, Durability - атомарность, согласованность, изолированность, долговечность данных), хорошая масштабируемость, поддержка популярных языков программирования (Java, Python, Ruby), мощный механизм обхода графа, подробная документация.
Данные динамической части могут быть как текстовыми, так и мультимедийными, поэтому для анализа каждого типа данных требуется определенный подход. Отдельной задачей при этом является анализ неструктурированных данных для выявления неявных семантических зависимостей, искажений, информационного мусора,. Эта задача может быть решена при помощи сочетания встроенных механизмов поискового робота и прикладных программных модулей на основе фреймворка для разработки и выполнения распределенных программ Hadoop [3, 9].
Анализ текстовых данных социального профиля
В настоящее время для обработки неструктурированных текстовых данных аналитиками применяются методы интеллектуального анализа текстов и обработки естественного языка [6]. Также могут использоваться методы анализа тональности для определения эмоциональной окраски текстов и возможного выявления в них неявного или скрытого смысла [7].
Неструктурированный текст, являющийся исходным при построении социального профиля, может включать: электронные письма, публикации (посты, комментарии на социальных ресурсах), электронные документы, списки, расшифровки изображений и аудиозаписей, статистические и геоданные и т.д. В подсистеме анализа социальных связей и зависимостей осуществляются поиск и разделение по группам выражений, которые станут основой для узлов и связей социального графа. Анализ текстов состоит из четырех этапов, представленных на рис. 1.
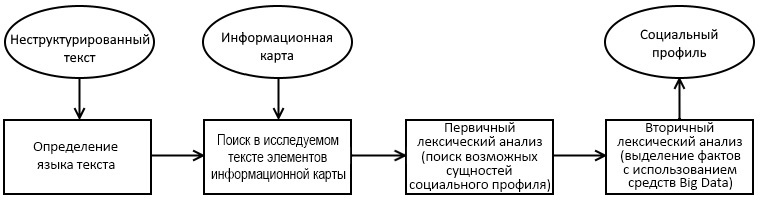
Рис. 1. Последовательность шагов анализа неструктурированного текста
Первым шагом анализа неструктурированных текстовых данных социального профиля является определение исходного языка для каждого элемента. Затем в текстах осуществляется поиск записей, входящих в информационную карту. Это обеспечит основу для последующего выстраивания связей социального профиля.
Дальнейший этап анализа заключается в распознавании именованных сущностей и извлечении признаков. Полученные результаты являются кандидатами на роль объектов социального профиля. При этом необходимо учитывать наличие синонимов, производных слов, транскрипций для каждого объекта.
После получения коллекции объектов социального профиля начинается извлечение информации и связей из неструктурированных данных для формирования целостной картины социального профиля. На данном этапе необходимо наличие средств обработки естественного языка, в частности заполненных тезаурусов правил синтаксического и лексического анализа текста. Желательно наличие отдельного словаря для оценки настроений.
Ввиду очень большого количества обрабатываемых данных предлагается использовать решения на основе технологии Big Data. В качестве примера рассмотрим применение программного средства IBM Content Analytics, которое осуществляет поиск фактов на основе анализа контента, просмотра и импорта содержимого, синтаксический разбор и анализ содержимого, моделирование и прогнозирование, разработку интеллектуальных фильтров и создание пригодного для поиска индекса [8].
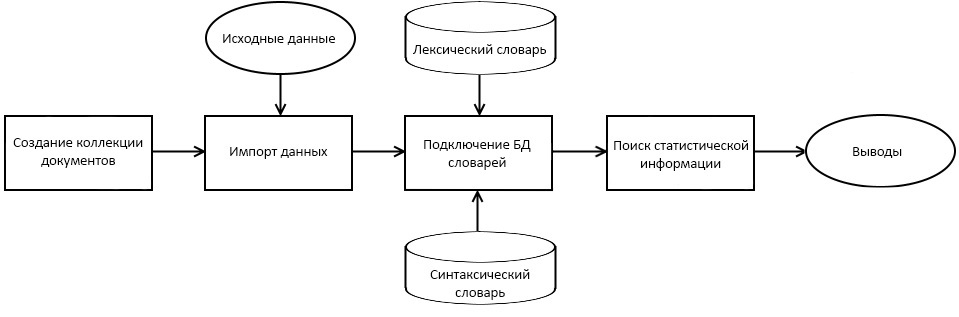
Рис. 2. Схема алгоритма анализа текстов в IBM Content Analytics
Рассмотрим алгоритм работы с Content Analytics (рис. 2). Первоначально создается коллекция документов – специальная индексируемая структура для работы со срезами данных или ограниченными совокупностями однородных значений по некоторому классификационному признаку. В нее импортируют исходные данные из различных источников. Далее подключаются базы данных словаря и синтаксических правил.
Затем поиск статистической информации осуществляется либо с помощью баз данных словарей обработки естественного языка, либо посредством запросов из ключевых слов. Тезаурусы состоят из локальной БД, xml-файла и собственно словаря в формате dict. Такие словари заполняются наиболее характерными выражениями из текстов исходных данных, после чего из них лексическим анализатором получают другие формы слов. Это повышает качество анализа и способствует нахождению информации, на основе которой делают статистические выводы.
Результаты выделяются в тексте во вкладке Documents. Вкладка Facets показывает статистические данные результатов (например, количество повторений в тексте) в виде диаграмм. Пример диаграммы среза по ключевому слову «Возраст» показан на рис. 3 [8].
Рис. 3. Пример запроса для среза данных в Content Analytics
Также возможно применение системы IBM BigInsights, использующей фреймворк Hadoop [9] и модель распределенных вычислений MapReduce [10] для выполнения задачи текстового анализа. Встроенные функции системы включают нормализацию, разметку, идентификацию языка, классификацию текстов для фильтрации спама, распознавание и интеграцию сущностей, анализ настроений, извлечение связей [11]. Их можно настраивать с помощью словарей для анализа настроений и списка объектов для распознавания сущностей. Также имеются решения для извлечения отраслевых ключевых показателей для избранных отраслей.
Результаты работы BigInsights можно использовать как исходные для других внешних обработчиков, в частности для определения неявных связей внутри данных социального профиля.
Выявление неявных зависимостей в данных социального профиля
Результаты анализа неструктурированных данных, даже с использованием специализированных средств NLP (англ. natural language processing - обработка естественного языка,), могут быть несовершенными: используемые тезаурусы могут быть неполными, исходные данные содержать лингвистические ошибки или иметь двоякий смысл. Также может содержаться скрытая информация, которую можно определить лишь косвенно. Для разрешения подобных проблем наиболее подходят средства визуального анализа, в качестве которых предлагается использовать программный инструментарий IBM i2. Он включает в себя следующие компоненты [8]:
- Text Chart – модуль для визуализации неструктурированных текстов, позволяет оперативно преобразовывать текстовую информацию в структурированный и легко анализируемый графический формат;
- Analyst's Notebook - предоставляет возможности быстрого сопоставления, анализа и наглядного представления данных из различных источников, обнаружения ключевой информации среди данных;
- iBase - позволяет совместно работающим коллективам аналитиков собирать, контролировать и анализировать данные из нескольких источников в единой защищенной рабочей среде для решения повседневных проблем путем исследования и анализа взаимосвязей в больших объемах сложно структурированной и неструктурированной информации.
Исходя из результатов анализа текстовых данных с помощью BigInsights и Content Analytics создается математическая модель для постройки iBase базы данных социального профиля. На ее основе строится граф, задающий возможные взаимосвязи между сущностями социального профиля, пример которого представлен на рис. 4.
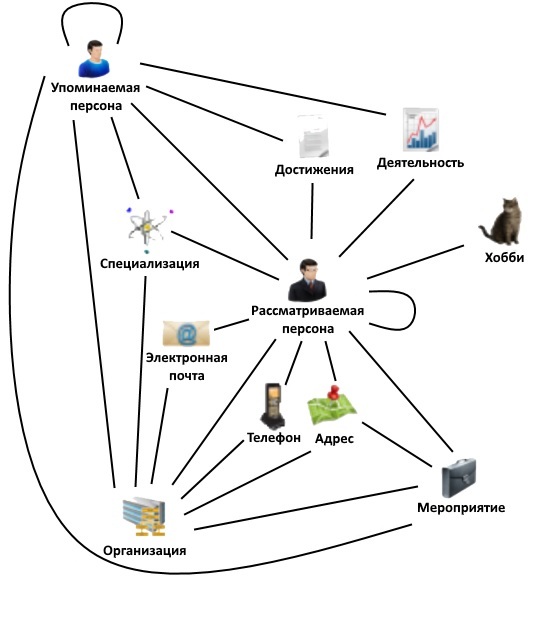
Рис. 4. Образец графа типов сущностей социального профиля
В качестве вершин графа выступают типы объектов, характеризующие рассматриваемую персону или связанные с ней определенным образом:
- рассматриваемая персона – центральный объект социального профиля, фактически состоит из данных информационной карты и сопутствующих сведений из динамического контента;
- упоминаемая персона – информация о лице, которое имеет связь с рассматриваемой персоной;
- организация – информация о различных учреждениях, которые связаны с персонами из социального профиля;
- мероприятие – информация о событии, объединяющем группу людей по некоторым общим признакам;
- адрес – географическое расположение, относящееся к конкретному человеку, организации или мероприятию;
- деятельность – информация о занятости лица, не связанной с конкретной организацией (например, писательство или благотворительность);
- специализация – конкретное направление деятельности лица или организации;
- хобби – информация об увлечениях людей;
- достижения – сведения о результатах деятельности лица, включая авторский контент;
- телефон – номер телефона, код и сопутствующая информация;
- электронная почта – адрес электронной почты, принадлежащий конкретному человеку или организации.
Основная работа по выявлению связей и зависимостей производится в программе IBM i2 TextChart. Анализ данных выполняется по следующему алгоритму:
1) данные социального профиля заносятся в проект Text Chart через импорт CSV-файла с исходной информацией;
2) в тексте выделяется первая попавшаяся важная информация, после чего проводится поиск повторений и синонимов по всему тексту с помощью средства Find;
3) результаты добавляются в проект как сущности социального профиля (рассматриваемая персона, деятельность и тд.);
4) в тексте выделяются слова, выражающие отношения между созданными объектами, и в окне с создаваемым графом зависимостей выбираются соответствующие объекты;
5) нажатием Insert Link выбирается требуемый тип связи, после чего выражения добавляются в качестве связей;
6) посредством навигации между результатами поиска сущностей аналогичным образом добавляются новые объекты и атрибуты уже существующих;
7) при нахождении противоречивой информации подсчитываются записи для каждого из вариантов, после чего делается вывод об их истинности: ложная информация удаляется из социального профиля или проводится уточняющий поиск.
Сущности Text Chart обладают уникальным индексом и наименованием, состоящим из метки в исходном тексте и значения, присвоенного аналитиком. Также существует возможность наличия нескольких значений у одного атрибута, за счет чего обеспечивается нахождение всех возможных интерпретаций отдельной сущности.
Результатами визуального анализа являются социальный граф и iBase БД социального профиля. Помимо скрытой информации, выявленной непосредственно во время анализа, возможно нахождение неявных связей на полученном графе социального профиля.
Методы анализа мультимедиаинформации социального профиля
В отличие от текстовых данных, мультимедиаконтент трудно поддается анализу с использованием классических средств, поэтому приходится прибегать к использованию решений на основе больших данных, нейронных сетей и машинного обучения. Примерами таких систем можно считать Google Analytics, MS Azure, Multimedia Mining Marvel, Quaero. Наиболее часто встречающейся мультимедийной информацией являются изображения и аудиозаписи. Существует ряд стратегий анализа мультимедиа данных [12]. Для обработки неструктурированной информации социального профиля используется целостная стратегия.
В рамках построения социального профиля мультимедиаконтент может рассматриваться в двух различных вариантах:
- Данные мультимедиа, просматриваемые и создаваемые исследуемым лицом, – информация, которая может говорить о деятельности и предпочтениях персоны. Также сюда относится и авторский контент. Задача анализа состоит в сравнении мультимедийных объектов с существующими образцами в сети Интернет и внутри социального профиля (например, определение музыкальных предпочтений по нескольким аудиозаписям).
- Контент, содержащий в себе сведения непосредственно о рассматриваемом лице. Целью анализа является выделение существенной информации из самого мультимедийного объекта (например, распознавание эмоций на фото, выделение смысловых выражений из аудиозаписей).
Для обработки мультимедийной информации первой категории целесообразно использовать контентный метод анализа [13], суть которого состоит в разбиении данных на составные части и их прямом сравнении. Для упомянутого выше примера определения музыкальных предпочтений будет выполняться следующий алгоритм. Сначала у существующих в базе социального профиля аудиозаписей проверяются ID3-теги на наличие исполнителя и жанра музыки. Если такие теги найдены, то они записываются в таблицу предпочтений. В ином случае производится сравнительный анализ аудиозаписи с образцами из Интернета (средствами утилит AudioTag, Shazam, Google Sound Search), и после обнаружения совпадения искомые теги добавляются в таблицу. По завершении обработки всех имеющихся аудиозаписей производится подсчет тегов и делается вывод о преобладании определенного жанра или исполнителя в выборке.
Пользовательский контент может содержать различные идентификационные метки как в сервисной информации (данные об авторе, устройстве, на котором был создан контент, геометки), так и внутри самой мультимедийной сущности. Такими метками могут быть: авторская подпись или водяной знак, характерный авторский стиль объекта, упоминания автора в комментариях и т.д. Часть этой информации является неявной, поэтому возможности автоматической обработки пользовательского контента весьма ограничены. Желательно использование средств визуального анализа. Сам алгоритм обработки будет отличаться тем, что помимо текстовой информации, извлеченной из мультимедийных объектов, нужно учитывать абстракции, которые добываются вручную и имеют нечеткую интерпретацию.
Другой задачей анализа пользовательского контента является определение вариантов использования мультимедийных сущностей. В данном случае перед аналитиком стоит цель связать конкретный мультимедийный объект с текстовым определением смысла события, в котором этот объект упоминается. Средствами Big Data в Интернете осуществляются поиск всех возможных ситуаций применения мультимедийной сущности и дальнейший статистический разбор сопутствующего текста с выделением тональности. Здесь, так же как и в предыдущем случае, рекомендуется использовать средства визуального анализа.
Рассмотрим подробнее вторую категорию. Для еe анализа используется контентно-интерпретационный метод [13], согласно которому составным частям мультимедийных данных присваиваются понятия на формальном языке, после чего выстраиваются связи между ними. Подходы к анализу аудио- и графической информации различаются между собой.
Обработка аудиоинформации
Основным направлением анализа аудиозаписей при построении социального профиля является распознавание речи и ее интонации. Результатами аудиоанализа являются: звуковые характеристики голоса рассматриваемой персоны, прикрепляемые к социальному профилю; распознанные тексты, связывающиеся с исходной записью. Также могут учитываться характеристики голоса иных лиц из анализируемого аудиофайла для сравнения с другими социальными профилями. Причем звуковые характеристики голоса не могут рассматриваться в качестве элемента информационной карты, так как, как правило, значительно изменяются в зависимости от возраста и состояния персоны, окружающей обстановки и качества записи.
В настоящее время существует достаточное количество свободно распространяемых систем распознавания речи с открытым исходным кодом: CMU Sphinx, Julius, HTK, Praat, SHoUt, VoxForge и др. Многие из них основаны на использовании скрытых марковских моделей и нейронных сетей. Звуковые характеристики голоса включают в себя спектрально-временные, кепстральные, амплитудно-частотные и признаки нелинейной динамики.
Следует упомянуть, что в русском языке существует семь видов интонационных конструкций (3 вопросительных, 2 восклицательных, 2 повествовательные). Распознавание интонации речи человека может проходить в три этапа: запись речи человека и разделение ее на законченные интонационные конструкции, выделение тона голоса в каждой из частей, построение классификатора интонационных конструкций [14]. Точность работы подобного алгоритма зависит от качества и продолжительности записей, особенностей речи и т.д.
Обработка графической информации
Анализ графической информации включает в себя: распознавание образов, текста и сопоставление результатов с датой создания рассматриваемого файла. Подходы к распознаванию графической информации делятся на три категории: методы перебора, искусственные нейронные сети и поиск контуров объекта с дальнейшим исследованием их свойств. Технология OCR (англ. Оptical character recognition - оптическое распознавание символов) позволяет находить печатный и в меньшей степени рукописный текст. Качество исходного изображения сильно влияет на конечный результат алгоритмов распознавания. Как и в случае с анализом аудио, распознанный на изображении текст должен привязываться к исходному объекту и в дальнейшем рассматриваться с помощью средств текстовой аналитики. После завершения обработки изображения полученные данные сводятся в результирующую таблицу, содержащую следующие ключевые параметры: распознанные лица, их эмоции, список надписей, данные об окружении (распознанные объекты), сервисная информация об изображении (размер, дата создания, название и др.).
Распознавание образов в рамках построения социального профиля подразделяется на: поиск лиц на изображениях, определение их выражений, а также выделение элементов окружения. Услуги распознавания лиц предоставляют такие сервисы, как ASID, FaceID, FindFace, Vissage Gallery. Распознавание эмоций является более сложной процедурой, основными проблемами которой являются определение положения и цвета лица, степень освещения, наличие посторонних объектов на переднем плане изображения. Несмотря на это, существуют готовые решения: FaceReader, FaceSecurity и др. Разработка систем определения элементов окружения недостаточно развита на сегодняшний день, поэтому для решения этой задачи целесообразно использовать специально обученную нейронную сеть.
Заключение
Степень проработанности аналитической подсистемы построения социального профиля влияет на информативность и корректность конечных результатов исследования. Особенно это касается обработки мультимедийных данных, ввиду их многообразия и трудной автоматизированной обработки. В рамках текущей работы был приведен обзор имеющегося опыта в области аналитики неструктурированных текстов социальных медиа и мультимедийного контента, а также рассмотрена возможность их применения в задаче построения социального профиля.
Показано, что автоматизированная обработка неструктурированных текстовых данных с использованием средств Big Data, визуального анализа и обработки естественного языка на примере использования программных продуктов IBM BigInsights, Content Analytics, i2 позволяет построить подробный граф, учитывающий явные и скрытые взаимосвязи между объектами социального профиля.
Предложен обзор существующих подходов к анализу мультимедийного контента, а также рассмотрена возможность их применения в задаче построения социального профиля. Выявлено, что для обработки аудиоданных возможно использование уже существующих алгоритмов, а анализ графической информации требует совершенствования технологии распознавания.
1. Бождай, А. С. Использование технологий Big Data для построения социального профиля человека на основе открытых источников информации / А. С. Бождай, А. Ю. Тимонин // Вестник Пензенского государственного университета. - 2 (10). - Пенза: Издательство Пензенского государственного университета. - 2015. - с. 140-144.
2. Бождай, А. С. The Process of Personal Identification and Data Gathering Based on Big Data Technologies for Social Profiles. / А. С. Бождай, А. Ю. Тимонин, А. М. Бершадский // Digital Transformation and Global Society. DTGS 2016. Communications in Computer and Information Science, vol. 674. - Санкт-Петербург, 22-24 июня 2016 г. - Springer International Publishing, Switzerland. - 2016. - с. 576-584.
3. Бождай, А. С. Research of filtration methods for reference social profile data / А. С. Бождай, А. Ю. Тимонин, А. М. Бершадский // EGOSE '16 Proceedings of the International Conference on Electronic Governance and Open Society: Challenges in Eurasia. - Санкт-Петербург, 22-23 ноября 2016 г. - ACM Press, New York, NY, USA. - 2016. - с. 189-193.
4. Apache HBase ™ Reference Guide // Официальный сайт проекта Apache HBase. - 2016. [Электронный ресурс] URL: http://hbase.apache.org/book.html (дата обращения 24.03.2017)
5. Официальный сайт Neo4j: The World's Leading Graph Database. - 2017. [Электронный ресурс] URL: https://neo4j.com (дата обращения 24.03.2017)
6. Большакова, Е. И. Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб. пособие / Е. И. Большакова, Э. С. Клышинский, Д. В. Ландэ, А. А. Носков, О. В. Пескова, Е. В. Ягунова - М.: МИЭМ, 2011. - 272 с.
7. Меньшиков, И. Л. Анализ тональности текста на русском языке при помощи графовых моделей / И. Л. Меньшиков // Доклады всероссийской научной конференции АИСТ’2013: сборник статей. - Екатеринбург, 2013. - С. 151-155.
8. Шмид, А. В. Новые методы работы с большими данными: победные стратегии управления в бизнес-аналитике. Научно-практический сборник. Под редакцией доктора технических наук, профессора А.В. Шмида. - М.:ПАЛЬМИР, 2016. - 528с.
9. Официальный сайт проекта Apache Hadoop. - 2017. [Электронный ресурс] URL: http://hadoop.apache.org (дата обращения 24.03.2017)
10. Hadoop 1.2.1 Documentation: MapReduce Tutorial. - 2013. [Электронный ресурс] URL: http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial (дата обращения 24.03.2017)
11. Лоза, К. Изучаем платформу расширенной аналитики: Часть 3. Анализ неструктурированного текста с использованием шаблонов / К. Лоза, А. Сатхи, М. Томас // IBM developerWorks. - 2014. [Электронный ресурс] URL: http://www.ibm.com/developerworks/ru/library/ba-adv-analytics-platform3/ (дата обращения 24.03.2017).
12. Давыдов, А. А. Системная социология: анализ мультимедийной информации в Интернете / А. А. Давыдов // Официальный сайт ИC РАН. - 2009. [Электронный ресурс] URL: http://www.isras.ru/publ.html?id=1257 (дата обращения 24.03.2017).
13. Яковлев, В. Е. Макромедиа: анализ мультимедиа информации. M-Lang / В. Е. Яковлев // Молодой ученый. - 2011. - №4. Т.1. - с. 105-108.
14. Левин, А. И. Распознавание интонации в непрерывной речи человека / А. И. Левин, П. Е. Минин, А. Д. Егоров // XIX Международная телекоммуникационная конференция молодых ученых и студентов "Молодежь и наука" Тезисы докладов. Ответственный редактор О. Н. Голотюк. - Москва, 01 октября - 10 декабря 2015 г. - Москва: Национальный исследовательский ядерный университет "МИФИ" - 2015. - с. 109-110.
