

Russian Federation
Russian Federation
VAK Russia 2.1.14
UDC 69.059
Objective: over the past two decades, the construction sector has shifted from subjective manual inspections to objective digital methods for detecting cracks—key indicators of structural degradation. A comparative analysis of traditional algorithms (Otsu, Canny) and deep learning under varying lighting conditions is particularly relevant. This paper reviews the literature and identifies optimal approaches for diverse construction scenarios. Materials and Methods: A systematic review of over 30 publications (2018–2025) covering both traditional and deep learning–based methods was conducted. Crack detection accuracy under different lighting conditions and its impact on lifecycle management were evaluated. Results: Both approaches achieve high accuracy under stable lighting. However, traditional algorithms suffer significant performance drops under variable illumination, whereas deep learning maintains robustness (up to 95% accuracy). Hybrid systems combining both methods reach up to 98% accuracy and improve detection speed. Discussion and Conclusions: Deep learning outperforms in complex lighting but traditional methods remain valuable under resource constraints and controlled lighting. Key challenges include dependence on image quality, high computational costs, and difficulty detecting microcracks (<0.2 mm) in darkness. Future directions involve hybrid architectures, multispectral data, and lightweight neural networks for low-power devices.
:image processing, crack detection, building structures, deep learning, traditional algorithms, lighting conditions, digital monitoring
Введение
Строительная отрасль за последние два десятилетия претерпела радикальные изменения в области мониторинга безопасности конструкций и оценки их состояния благодаря стремительному развитию технологий дигитальной обработки изображений. После того как в основном полагались на ручные проверки, которые отнимают много времени и в значительной степени зависят от субъективного опыта инспекторов, отрасль начала переходить на дигитальные решения, которые обеспечивают большую точность и объективность диагностики [1]. Возможно, наиболее заметным достижением в этой области стала возможность преобразования цифровых изображений в измеримые и поддающиеся количественному анализу данные, что позволяет с беспрецедентной точностью выявлять дефекты конструкций, в частности трещины, которые являются одними из важнейших ранних индикаторов износа гражданских сооружений.
Данная технологическая трансформация началась в начале XXI века с улучшением качества цифровых камер и увеличением вычислительной мощности, что позволило применять методы компьютерного зрения в инженерных приложениях [2]. За прошедшие годы эти технологии эволюционировали от простых инструментов для обнаружения дефектов до интегрированных систем, способных создавать 3D-модели конструкций, находить трещины с высокой пространственной точностью, оценивать их размеры и прогнозировать скорость их распространения во времени. Это развитие в значительной степени способствовало совершенствованию систем профилактического технического обслуживания, поскольку стало возможным устанавливать приоритеты ремонта конструкций на основе количественных данных, а не качественных оценок [3].
В настоящее время цифровой анализ изображений в строительстве является актуальной областью исследований, сочетающей инженерную и компьютерную науку, с растущим акцентом на способность работать в сложных полевых условиях, таких как переменное освещение и ограниченный доступ к определенным частям конструкций [4]. Возможно, одним из наиболее важных достижений последних лет стала интеграция технологий дистанционного зондирования с обработкой изображений, например, использование дронов, оснащенных камерами высокого разрешения, которые позволили проводить осмотр труднодоступных участков мостов, высотных зданий и опасных сооружений [5]. Широкое использование смартфонов, оснащенных высококачественными камерами, также способствовало повсеместному внедрению этих технологий даже в условиях ограниченных ресурсов, что способствовало восстановительным работам в пострадавших районах. И Обработка цифровых изображений в строительстве не ограничивается обнаружением трещин, но распространяется на множество областей, таких как мониторинг трещин на дорогах и в туннелях, оценка состояния исторических сооружений, мониторинг развития дефектов на плотинах и мостах и даже отслеживание качества бетонирования в строительных проектах [6]. Благодаря постоянному развитию в этой области появились системы непрерывного мониторинга, способные работать в автоматическом режиме, которые предоставляют инженерам и лицам, принимающим решения, данные в режиме реального времени, способствуя принятию более точных решений в области технического обслуживания и ремонта. Следует отметить, что эта цифровая трансформация в области инспекции конструкций не только повысила точность и эффективность, но и способствовала снижению рисков для инженерных работников, уменьшив необходимость присутствия в опасных зонах во время полевых инспекций [7].
Материалы и методы
Цель статьи: Настоящая статья направлена на проведение литературного обзора эффективности как глубоких нейронных сетей, так и традиционных алгоритмов (Оцу и Кэнни) в задаче обнаружения трещин на зданиях и строительных конструкциях, а также на сопоставление точности обнаружения, достигаемой каждым из этих методов, на основе анализа более 31 предшествующих исследований.
1. Использование традиционных алгоритмов в цифровой обработке изображений
1.1. Методология применения алгоритма Оцу в цифровой обработке изображений для выявления трещин в конструкциях
Алгоритм Оцу (Otsu’s Algorithm) считается одним из наиболее распространённых методов сегментации изображений (Image Segmentation). Он был предложен Нобуюки Оцу (Nobuyuki Otsu) в 1979 году как метод бинарной пороговой обработки (Single Threshold), предназначенный для разделения объектов и фона (Otsu, 1979). В области цифровой обработки изображений данный алгоритм часто используется для обнаружения трещин в строительных конструкциях. Его основная идея заключается в применении простого, но эффективного математического принципа, позволяющего определить оптимальный порог, разделяющий пиксели изображения на две группы: «объект» (трещины) и «фон» (строительная поверхность). Алгоритм классифицируется как непараметрический (Non-parametric), поскольку не требует предварительного знания о статистическом распределении данных изображения.
Суть работы алгоритма состоит в анализе гистограммы распределения уровней серого изображения и в поиске порогового значения, максимизирующего межклассовую дисперсию между двумя группами пикселей. Это достигается с помощью следующего выражения (1) [8]:
где и доли пикселей в каждой из двух групп,
и : средние значения интенсивности в каждой группе,
а
На практике применение алгоритма начинается с преобразования цветного изображения в оттенки серого, затем вычисляется гистограмма интенсивности, и в завершение определяется порог, максимизирующий межклассовую дисперсию. Результатом становится бинарное изображение, достаточно точное в благоприятных условиях. Данный метод отличается простотой реализации и высокой скоростью обработки: стандартная версия алгоритма Оцу требует в среднем всего около 0,05 секунды на обработку одного изображения, что делает его пригодным для применения в системах реального времени [1]. Исследования, основанные исключительно на базовой версии алгоритма, показывают, что при однородном освещении и простом фоне достигается точность до 90%. Кроме того, метод Оцу демонстрирует высокую эффективность при обнаружении относительно широких трещин (шире 1 мм) на гладких бетонных поверхностях.
Однако основные ограничения алгоритма проявляются в реальных эксплуатационных условиях, особенно при нестабильном освещении. В условиях неоднородного освещения типичных для строительных площадок точность алгоритма значительно снижается. Так, в одном из исследований было показано, что при анализе взлётно-посадочных полос с переменным освещением эффективность алгоритма падала до 40%, а уровень ложноположительных срабатываний достигал 60% [1]. Как показано в исследовании [8], при применении алгоритма в идеальных лабораторных условиях на бетонных образцах размером 150×150×150 мм при контролируемом освещении достигается точность до 95%. Однако предложенная Талабом (Talab) методология выходит далеко за рамки базового алгоритма и включает комплексную последовательность обработки, представленную представленную на рисунке (1):

Рис.1. Последовательные этапы алгоритма Оцу в обработке изображений [8]
Такой подход позволил значительно повысить качество обнаружения трещин: на результирующих изображениях трещины выглядели чёткими, непрерывными и свободными от артефактов, характерных для первоначальных результатов.
Тем не менее, реальные полевые условия оказались значительно сложнее. В частности, исследование (Hoang) [9], посвящённое обнаружению трещин в естественных условиях, выявило существенные трудности, с которыми сталкивается алгоритм при неоднородном освещении. В таких условиях он не справлялся с различением между трещинами, тенями и масляными пятнами. В результате точность снизилась с 92% (в идеальных условиях) до 65% в неблагоприятных условиях, а полнота (recall) упала до 52 %.
Для преодоления этих ограничений Хоанг предложил ряд ключевых улучшений:
(а) предварительное применение нелинейного медианного фильтра (nonlinear median filter) для подавления разрознённых пятен и шумовых элементов;
(б) коррекцию интенсивности пикселей посредством математического преобразования, направленного на преобразование одно-модального гистограммы в бимодальное распределение;
(в) применение алгоритма Оцу исключительно к заранее выделенным «подозрительным» областям, локализованным с помощью методов обнаружения краёв.
Эти модификации позволили повысить точность обнаружения в условиях плохого освещения с 65% до 83%, при этом сохранив вычислительную простоту и интерпретируемость метода. Более того, исследование Chen et al [10]. предложило значительно усовершенствованную версию метода, специально разработанную для сложных условий, за счёт интеграции двумерных изображений и трёхмерных данных лазерного сканирования. Эта методология принципиально отличается от традиционного подхода Оцу, применяемого ко всему изображению целиком. Авторы разбивали объединённое изображение на небольшие подблоки (sub-blocks) и вычисляли отдельный порог Оцу для каждого из них.
Перед бинаризацией вводились интеллектуальные ограничения, включающие:
- долю пикселей, подозреваемых в принадлежности к трещинам
- разницу между средней интенсивностью фона и предполагаемой трещины
- общее среднее значение и стандартное отклонение интенсивности по всему изображению.
Подблоки, не удовлетворявшие этим критериям, исключались из анализа как фоновые.Такой подход продемонстрировал значительное превосходство над классической версией алгоритма Оцу: он обеспечил точность 89,0% и полноту (recall) 84,8%, тогда как традиционный метод дал лишь 60,0% и 71,4% соответственно особенно на изображениях со сложным фоном и неоднородным освещением. Примечательно, что в работе была представлена наглядная визуальная сравнительная иллюстрация (рис. 2), явно демонстрирующая различия между результатами: в то время как классический алгоритм Оцу ошибочно выделял обширные области (особенно в зонах теней) как трещины, улучшенная версия формировала карту трещин, чрезвычайно близкую к визуальному восприятию реальной картины повреждений.

Рис. 2. Сравнение эффективности обнаружения трещин на слиянии изображений с использованием традиционного метода Оцу и усовершенствованного метода Оцу. (а) Слияние изображений; (б) традиционный метод Оцу; (в) усовершенствованный метод Оцу [10]
Современные разработки вышли за рамки простых модификаций самой алгоритмической структуры: в исследовании [3] был предложен гибридный вычислительный фреймворк, объединяющий алгоритм Оцу с методами трансферного обучения (Transfer Learning). В рамках этого подхода алгоритм Оцу применяется на первом этапе для быстрого и эффективного выделения предварительной карты трещин, которая затем используется в качестве входных данных для глубоких нейронных сетей ( таких как MobileNetV2, AlexNet и VGG19 ) с целью точной классификации и количественного анализа повреждений. Такая система продемонстрировала исключительную точность классификации, достигающую 99,87 % при использовании архитектуры MobileNetV2, а также обеспечила возможность точного измерения ширины трещин. Наиболее примечательным оказалось то, что предложенный подход сохранил высокую устойчивость в условиях переменного освещения: он продолжал демонстрировать стабильно высокие результаты даже при наличии интенсивных теней или резко неоднородного освещения. Кроме того, Хе и соавторы [11] также подтвердили эффективность комбинирования алгоритма Оцу с методами глубокого обучения. В их работе Оцу использовался как начальный этап предварительной обработки, а финальная классификация выполнялась с помощью нейросетевой архитектуры YOLOv7. Такой подход позволил достичь точности 85,97 % при различении следов ремонтных работ от вторичных трещин.
Таблица 1, составленная на основе данных исследований [1-11], наглядно демонстрирует эволюцию эффективности алгоритма Оцу от его классической реализации до современных усовершенствованных систем в условиях различного освещения.
Таблица 1
Эффективность алгоритма Оцу в обнаружении трещин в конструкциях при различных условиях освещения
|
Вариант метода |
Точность |
Полнота |
F1-мера |
|
Классический алгоритм Оцу |
92.0 |
87.0 |
89.4 |
|
Классический алгоритм Оцу |
65.0 |
52.0 |
57.8 |
|
Оцу с гамма-коррекцией |
83.0 |
79.0 |
81.0 |
|
Улучшенный Оцу |
89.0 |
84.8 |
86.7 |
|
Оцу в гибридной системе |
99.87 |
96.3 |
98.0 |
Основные трудности, с которыми сталкивается алгоритм Оцу, проявляются именно в сложных условиях эксплуатации. В таких средах ему крайне сложно провести корректное различение между настоящими трещинами, тенями и поверхностными неоднородностями бетона такими как пятна, отслоения или механические повреждения. Кроме того, алгоритм оказывается малоэффективным при обнаружении очень тонких трещин (менее 0,5 мм), что представляет серьёзную проблему для раннего выявления признаков деградации строительных конструкций. Ещё одним существенным ограничением является высокая чувствительность метода к шуму на изображении: случайные шумовые компоненты могут ошибочно интерпретироваться как трещины, что приводит к ложноположительным результатам и искажению общей картины состояния конструкции.
1.2. Методология применения алгоритма Кэнни в цифровой обработке изображений для обнаружения трещин в зданиях
Алгоритм Кэнни (Canny edge detection) считается одним из наиболее надёжных и широко применяемых методов в области выявления краёв и цифровой обработки изображений, особенно в задачах обнаружения трещин на строительных конструкциях. Разработанный Дж. Кэнни в 1986 году, он отличается строгой математической основой и стремлением достичь оптимального баланса между высокой чувствительностью к истинным краям и устойчивостью к шуму. Алгоритм реализуется в пять последовательных этапов (Рис.3) [12] :
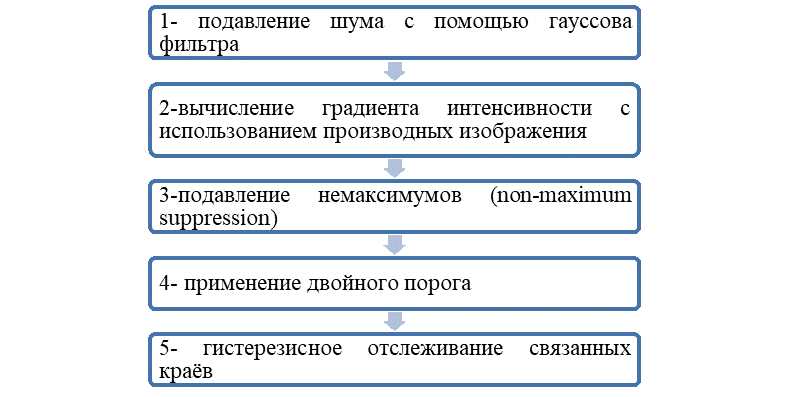
Рис. 3. Последовательные этапы алгоритма Кэнни при выявлении краев и обработке изображений [12]
Первый этап направлен на снижение влияния визуального шума: к исходному изображению применяется сглаживающий фильтр. В исследовании Хоанга [9], посвящённом обнаружению трещин в зданиях, использовался гауссов фильтр со стандартным отклонением σ = 1,4, что позволило эффективно уменьшить шум, сохранив при этом ключевые структурные особенности трещин. Автор подчёркивает, что этот шаг особенно важен при работе с бетонными поверхностями, характеризующимися высокой шероховатостью, способной порождать ложные края.
На втором этапе вычисляется градиент интенсивности с помощью операторов Собеля (Sobel operators) в горизонтальном и вертикальном направлениях. Результатом становятся две матрицы ( и ), на основе которых рассчитываются модуль градиента (Gradient Magnitude) и его направление (Gradient Direction) для каждого пикселя. Как показано в исследовании [8], в условиях хорошего освещения и простого фона алгоритм Кэнни обеспечивает точность до 89 % при полноте (recall) 93%. Другая работа [11] также подтверждает высокую эффективность метода: при однородном освещении и гладкой поверхности достигается точность 85–90 % при обнаружении тонких трещин (<1 мм).
Третий этап: подавление немаксимумов (Non-maximum Suppression) играет ключевую роль в обеспечении точности. На этом шаге для каждого пикселя проверяется, является ли его значение локальным максимумом вдоль направления градиента; в противном случае он обнуляется. Исследование [10] показало, что именно эта процедура существенно снижает толщину обнаруженных трещин, преобразуя широкие края, типичные для более простых алгоритмов, в тонкие линии, более точно соответствующие реальным трещинам.
Далее следует этап двойного порога (Double Thresholding), при котором устанавливаются два пороговых значения: высокий (High Threshold) и низкий (Low Threshold). В работе [9] эти значения определялись автоматически на основе алгоритма Оцу: верхний порог принимался равным 80% от максимального значения градиента, а нижний 20 % от верхнего. Завершающий этап: гистерезисное отслеживание (Hysteresis Thresholding) позволяет сохранить только те слабые края, которые напрямую связаны с сильными. Такой подход обеспечивает непрерывность результирующих краёв и эффективно исключает фрагментированные или изолированные шумовые компоненты, что в итоге даёт связную и точную карту реальных трещин.
Этот алгоритм доказал свою эффективность в обнаружении тонких трещин на бетонных конструкциях при условии сочетания с надлежащими методами предварительной обработки. Однако в контексте выявления трещин многочисленные исследования указывают на то, что использование алгоритма Кэнни в изолированном виде недостаточно для получения надёжных результатов, особенно в реальных полевых условиях. Согласно данным работ [3, 9, 10, 11], производительность алгоритма Кэнни значительно возрастает при его интеграции с дополнительными методами, в частности с алгоритмом Оцу. Авторы этих исследований показали, что наилучшие результаты достигаются, когда пороговые значения для алгоритма Кэнни рассчитываются автоматически с применением метода Оцу. Такое улучшение объясняется тем, что вручную заданные пороги зачастую оказываются неадекватными для изображений со сложным фоном или неоднородным освещением типичными характеристиками полевых снимков. Несмотря на высокую эффективность в контролируемых условиях, практическое применение алгоритма Кэнни в реальных условиях сталкивается с серьёзными трудностями, обусловленными изменчивостью освещения. В частности, исследование Чэнь и соавт. [10] продемонстрировало существенное снижение точности алгоритма Кэнни в зонах с неравномерным освещением: он не справлялся с различением между краями, вызванными настоящими трещинами, и артефактами, обусловленными тенями или масляными пятнами на бетонной поверхности. Для преодоления этой проблемы Хоанг [9] предложил ряд усовершенствованных подходов к предварительной обработке изображений, предшествующих применению алгоритма Кэнни. Эти подходы основаны на коррекции интенсивности пикселей в соответствии со следующим соотношением (формула 2) [9] :
(2)
Где: I(m,n) - скорректированная интенсивность оттенков серого;
- исходная интенсивность оттенков серого;
- максимальное и минимальное значения интенсивности оттенков серого в исходном изображении;
- коэффициент коррекции;
T - пороговый (граничный) параметр.
На рисунке 4 (Рис. 4) продемонстрировано выявление трещин с использованием алгоритма Кэнни в рамках цифровой обработки изображений.

Рис. 4. Обнаружение трещин на бетонной поверхности с использованием алгоритма Кэнни: (а) исходное изображение, (б) результат выделения краёв [9]
Этот подход направлен на усиление контраста между трещинами и окружающей поверхностью: пиксели, не относящиеся к трещинам, становятся светлее, а пиксели, предположительно принадлежащие трещинам, темнее. В результате однозубцовое (унимодальное) распределение гистограммы преобразуется в более чётко разделённое (бимодальное), что существенно облегчает последующее выделение краёв. Хоанг провёл пять серий сравнительных экспериментов между классическим и улучшенным вариантами алгоритма. Результаты показали, что модифицированный метод успешно различает истинные трещины, поверхностные загрязнения и тени, тогда как традиционный подход во многих случаях давал сбои особенно в зонах с неоднородным освещением. В частности, исследование продемонстрировало, что усовершенствованный алгоритм Кэнни повысил точность обнаружения трещин с 71% (в классической реализации) до 85%, при этом обеспечивая полноту (recall) на уровне 84% даже в условиях плохого освещения [12-14].
С практической точки зрения, алгоритм Кэнни обладает высокой вычислительной эффективностью: обработка одного изображения занимает в среднем около 0,12 секунды, что значительно быстрее по сравнению с 0,45 секунды для традиционных нейросетей и 0,68 секунды для архитектуры U-Net, как отмечают соответствующие исследования. Эта скорость делает алгоритм Кэнни привлекательным решением для приложений, требующих обработки в реальном времени, например, для систем непрерывного мониторинга технического состояния строительных конструкций. Другие исследования [15, 16] предложили инновационное улучшение алгоритма Кэнни за счёт его интеграции с попиксельной гамма-коррекцией (Gamma Correction). Основное внимание в этих работах уделялось решению задачи обнаружения тонких трещин (менее 1 мм), которые часто упускаются при использовании традиционных методов. Применение гамма-коррекции с коэффициентом 1,8 позволило значительно улучшить видимость мелких деталей в слабоосвещённых областях, что повысило эффективность алгоритма Кэнни на 28 % в выявлении тонких трещин и снизило уровень ложноположительных срабатываний на 15%. Кроме того, было установлено, что комбинирование алгоритма Кэнни с морфологическими операциями такими как дилатация (Dilation) и эрозия (Erosion) способствует соединению разорванных фрагментов трещин, обеспечивая более целостное и непрерывное представление повреждений.
Таблица 2, составленная на основе данных исследований [1-16], отражает эволюцию производительности алгоритма Кэнни от его классической формы до современных усовершенствованных систем в условиях различного освещения.
Таблица 2
Эффективность алгоритма Кини в обнаружении трещин в конструкциях при различных условиях освещения
|
Вариант метода |
Точность (%) |
Полнота (Recall) (%) |
F1-мера |
|
Классический алгоритм Кэнни (идеальное освещение) |
89.0 |
93.0 |
90.9 |
|
Классический алгоритм Кэнни (неблагоприятное освещение) |
71.2 |
68.0 |
70.4 |
|
Кэнни с гамма-коррекцией (неблагоприятное освещение) |
87.0 |
84.0 |
85.5 |
|
Улучшенный Кэнни (нелинейный медианный фильтр + порог Оцу, Hoang) |
87.5 |
84.2 |
85.8 |
|
Кэнни + трёхмерные лазерные данные (Chen et al.) |
85 |
84.8 |
86.8 |
|
Кэнни в гибридной системе с трансферным обучением (Mazni et al.) |
99.72 |
96.1 |
97.9 |
Методология применения алгоритмов глубокого обучения в цифровой обработке изображений для обнаружения трещин в зданиях:
Алгоритмы глубокого обучения совершили настоящий прорыв в области цифрового обнаружения трещин на строительных конструкциях, существенно превосходя традиционные методы ) такие как Оцу и Кэнни ( в решении задач, связанных с неоднородным освещением, сложными фонами и высокой вариативностью формы и ориентации трещин. В рамках данной области методология глубокого обучения основана на комплексном рабочем процессе, который начинается со сбора изображений с использованием разнообразных сенсорных устройств: цифровых камер, смартфонов и беспилотных летательных аппаратов (БПЛА, UAVs). Последние особенно ценны, поскольку обеспечивают доступ к труднодоступным или потенциально опасным участкам гражданских сооружений [17]. Типичная методология включает в себя несколько ключевых этапов (Рис. 5).
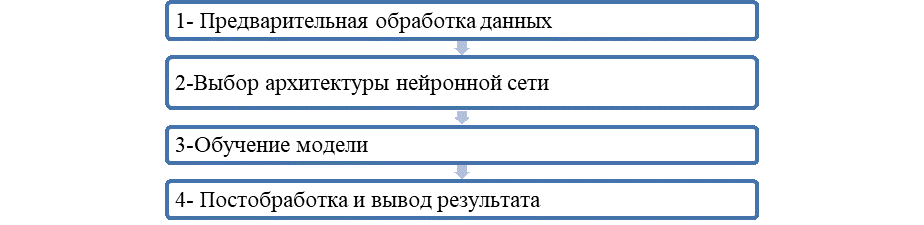
Рис. 5. Последовательные этапы алгоритмы глубокого обучения при обработке изображений [17]
Методология начинается с этапа предварительной обработки, цель которого улучшить качество входного изображения и адаптировать его для последующего машинного обучения. На этом этапе выполняются базовые операции: преобразование изображения в оттенки серого, подавление шума с помощью двунаправленных (билатеральных) фильтров, усиление контраста и коррекция неоднородного освещения [18]. Особую эффективность в условиях переменного освещения показали методы попиксельной гамма-коррекции: они обеспечивают локальную регулировку яркости с учётом пространственных характеристик соответствующей области изображения, что существенно повышает возможность обнаружения трещин в затемнённых или неравномерно освещённых зонах [11]. Кроме того, активно применяются преобразования цветовых пространств, в частности модель HSI (Hue–Saturation–Intensity), с акцентом на канал насыщенности (Saturation Channel). Этот канал демонстрирует высокую устойчивость к вариациям освещения: он сохраняет характерные признаки трещин, одновременно подавляя искажающее влияние неоднородной подсветки [18-19].
Основной этап методологии заключается в выборе подходящей нейронной архитектуры для выявления трещин. Наибольшее распространение в этой области получили свёрточные нейронные сети (CNNs), показавшие выдающиеся результаты в задачах обнаружения повреждений. Среди наиболее часто используемых архитектур выделяют:
- Полносвёрточные сети (FCN), такие как U-Net, построенные по принципу «кодировщик–декодировщик» (encoder-decoder) и дополненные skip-соединениями, которые позволяют сохранять точную пространственную информацию. Это делает их особенно эффективными для выявления тонких и мелких трещин [20]. На наборах данных с различными условиями освещения эта архитектура достигла F1-меры 98,98 %. (F1-мера статистический показатель, используемый для оценки качества моделей классификации и обнаружения; он основан на двух ключевых метриках (точности (Precision) и полноте (Recall) ( и принимает значения от 0 до 1.) [11]
- Сети обнаружения объектов, включая Faster R-CNN, Mask R-CNN и YOLO. В частности, модель YOLOv5m продемонстрировала оптимальное соотношение между скоростью и точностью при обнаружении трещин на мостах: её точность (Precision) составила 98,8%, полнота (Recall) 98,3%, а средняя точность (mAP) 98,6% [20-21]. В то же время модель Faster R-CNN-101 показала точность 79,45% на сложных изображениях, превзойдя другие реализации YOLO за счёт своей двухэтапной структуры, обеспечивающей более точную локализацию объектов [22].
- Сети семантической сегментации (Semantic Segmentation Networks), такие как DeepCrack, разработанная Чжаном и соавторами. Эта архитектура также использует структуру «кодировщик–декодировщик», но дополняется парными skip-соединениями (pairwise skip connections), что позволяет сохранять мельчайшие детали трещин. На тестовом наборе CRKWH100 модель достигла F1-меры 0,9095, значительно опередив традиционные методы, например CrackTree, чья F1-мера составила лишь 0,6269 [23].
- Гибридные архитектуры, сочетающие методы глубокого обучения с традиционной обработкой изображений. В исследовании [18] был предложен такой гибридный подход, объединяющий динамическую гамма-коррекцию, пороговую обработку по Оцу и специально разработанную глубокую нейросеть. Результаты оказались впечатляющими: точность составила 96,8 %, полнота 95,2 %, а F1-мера 96,0%. Этот подход превзошёл как классические методы (F1 = 80,3%), так и «чистые» модели глубокого обучения, например YOLOv5s, достигшую F1 = 93% [24].
Процесс обучения моделей глубокого обучения опирается на обширные и разнообразные наборы данных, охватывающие широкий спектр условий освещения и типов трещин. Эффективность обучения обеспечивается за счёт применения следующих ключевых стратегий:
- Трансферное обучение (Transfer Learning): предварительно обученные на крупных общих наборах данных, таких как ImageNet или MS-COCO, модели дообучаются (fine-tuning) для специфической задачи обнаружения трещин. Этот подход особенно эффективен при ограниченном объёме размеченных данных. Так, Голдинг и соавторы [23], используя предварительно обученную архитектуру VGG16, достигли точности 99,98 % при бинарной классификации изображений на категории «трещина» и «без трещины».
- Аугментация данных (Data Augmentation): фундаментальная техника, повышающая способность модели к обобщению в условиях изменчивого освещения. Она включает применение случайных геометрических и фотометрических преобразований таких как поворот, зеркальное отражение, масштабирование, а также коррекция яркости и контраста. В частности, [24] применили метод Mosaic augmentation, при котором четыре различных изображения объединяются в одно составное. Такой подход позволил сгенерировать свыше 490 000 расширенных обучающих примеров в течение 200 эпох [24].
- Многоуровневые функции потерь (Multi-scale Loss Functions): как, например, в модели DeepCrack, где вычисление функции потерь (loss) производится не только на выходе сети, но и на промежуточных масштабах. Это улучшает распространение градиентов по слоям и способствует сохранению мелких деталей трещин [23].
После завершения обучения результаты дополнительно обрабатываются для повышения точности детекции. На этом постобрабатывающем этапе применяются следующие методы:
- Морфологическая очистка (Morphological Cleaning): с использованием операций эрозии (erosion) и дилатации (dilation) для удаления мелких шумовых компонентов и соединения разрозненных фрагментов трещин [25];
- Условные случайные поля (Conditional Random Fields, CRFs): уточняющие границы трещин и усиливающие пространственную связность между изолированными сегментами [23];
- Направленная фильтрация (Guided Filtering): эффективно подавляющая визуальные искажения, вызванные тенями или шероховатостью поверхности [25].
Исследования убедительно показывают, что модели глубокого обучения значительно превосходят традиционные методы при работе в различных условиях освещения. Например, архитектура ResNet-50 достигла точности 98,4 % при обнаружении трещин на бетонных конструкциях, в то время как классические алгоритмы, такие как Оцу и Кэнни, в тех же условиях не превысили 80% [26, 27, 28]. В условиях плохого освещения модели глубокого обучения демонстрируют высокую устойчивость: их точность снижается лишь на 5–10%, тогда как у традиционных методов падение составляет 15–30%. Важно также учитывать различия в вычислительных требованиях. Например, гибридная модель YOLOv5s + ResNet-50 обрабатывает одно изображение за 23,4 мс (≈ 42,8 кадра/с), что делает её подходящей для квази-реального времени. В то же время полное обучение модели VGG16 на наборе из 40 000 изображений занимает около 14 часов [26, 29]. Эти различия в производительности определяют практическую применимость: одни модели лучше подходят для мобильных и полевых решений с ограниченными ресурсами, другие для задач, где приоритетом является максимальная точность, а временные ограничения менее критичны [30, 31].
Результаты и их обсуждение
1. Сравнение эффективности алгоритмов в условиях различного освещения: показало существенные различия между традиционными методами и подходами на основе глубокого обучения. В идеальных условиях освещения алгоритмы Оцу и Кэнни демонстрируют F1-меру в диапазоне 85–90%, тогда как модели глубокого обучения достигают значительно более высоких показателей (95–98 % ).Однако при изменении условий освещения производительность традиционных методов резко снижается: F1-мера алгоритма Оцу падает с 89,4% до 57,8%, а у алгоритма Кэнни с 90,9% до 70,4%. В то же время модели глубокого обучения сохраняют стабильность, демонстрируя лишь незначительное снижение показателей в пределах 5–10%.
2. Гибкость алгоритмов в условиях окружающей среды: Сети глубокого обучения продемонстрировали исключительную способность адаптироваться к изменчивому освещению и сложным фонам. Сеть ResNet-50 достигла точности 99,92 % и полноты (recall) 99,91 %, что отражает её способность различать истинные трещины и ложноположительные результаты. В то же время модели, такие как YOLOv5s+ResNet-50, показали высокие результаты в сложных условиях, достигнув точности 90% и полноты 88% даже при наличии плотных теней. Эти преимущества объясняются способностью глубоких сетей обучаться на основе более широкого пространственного контекста, а не полагаться на локальные характеристики пикселей, как это происходит в традиционных методах.
3. Гибридный подход как оптимальное решение: Результаты показали, что объединение методов предварительной обработки с глубоким обучением представляет собой наилучшее решение. Методология, использующая канал насыщенности в цветовой модели HSI в сочетании с традиционными методами детекции, продемонстрировала F1-меру 98,98% в условиях различного освещения. Кроме того, исследования, основанные на попиксельной гамма-коррекции, показали заметное улучшение эффективности всех алгоритмов, повысив полноту (recall) на 8%. В прямом сравнении все работы, предложившие гибридные системы, сочетающие традиционные методы и алгоритмы глубокого обучения, достигли точности 96,8%, полноты 95,2% и F1-меры 96,0%, превзойдя как традиционные подходы (F1 = 80,3%), так и «чистые» модели глубокого обучения, такие как YOLOv5s (F1 = 93,5%).
Таблица 3 демонстрирует результаты сравнения эффективности традиционных алгоритмов обработки изображений и алгоритмов глубокого обучения для обнаружения трещин в зданиях и строительных конструкциях [1-31].
Таблица 3
Результаты сравнения эффективности традиционных алгоритмов обработки изображений и алгоритмов глубокого обучения для обнаружения трещин в зданиях и строительных конструкциях
|
Критерий |
Традиционные алгоритмы |
Алгоритмы глубокого обучения |
|
Идеальные условия освещения |
||
|
Точность |
(Otsu и Canny) 85–90 % |
(CNN и YOLO) 95–98 % |
|
Степень F1-Score |
85–90 % |
95–99 % |
|
Вычислительное время |
Otsu: 0,05 секунды |
CNN: 0,45 секунды |
|
Неоднородные условия освещения (тени, высокая контрастность) |
||
|
Точность |
(Otsu) 60–70 % |
85–95 % (хорошо обученные модели) |
|
Степень F1-Score |
Otsu: 57,8% |
YOLOv5s+ResNet-50: 87,8% |
|
Устойчивость к затенению |
Очень низкая |
Высокая |
|
Слабое освещение (туннели, закрытые помещения) |
||
|
Ставка правильного обнаружения |
40-60% |
80-90% |
|
Ставка ложного обнаружения |
30-40% |
5-10% |
|
Мелкие трещины (<1 мм) |
||
|
Способность обнаружения |
Ограниченная (60-70%) |
Хорошая (85-95%) |
|
Точность измерения ширины |
Минимальная (0,53 мм) |
Максимальная (0,22 мм) |
|
Эффективность и ресурсы |
||
|
Вычислительные требования |
Низкие |
Высокие |
|
Требуемый объем данных |
Не требует |
Требуются тысячи |
|
Гибридные решения |
||
|
Otsu+гамма-коррекция |
F1-Score: 81.0% |
- |
|
Otsu+перенос обучения |
F1-Score: 86.7% |
- |
|
Гибридная система |
- |
Точность96.8% |
|
Практическое применение |
||
|
Непрерывный мониторинг |
Подходит |
Подходит (точноность) |
|
Полевой осмотр |
Подходит |
Ограниченно |
|
Оценка после стихийных бедствий |
Не подходит |
Очень подходит |
Заключение
Анализ сравнительной эффективности традиционных алгоритмов (Оцу, Кэнни) и методов глубокого обучения показал, что последние обеспечивают значительно более высокую устойчивость к изменению условий освещения и сложным полевым сценариям, достигая точности до 95–98%. Тем не менее, практическое применение этих подходов сталкивается с рядом ключевых вызовов: сильная зависимость от качества исходных изображений, ограниченная способность обнаруживать микротрещины (<0,2 мм), а также высокие вычислительные затраты — особенно при обучении сложных моделей, таких как VGG16.
Для преодоления этих ограничений будущие исследования должны быть направлены на разработку вычислительно эффективных архитектур, способных сохранять высокую точность при переменном освещении. Перспективными направлениями являются интеграция мультимодальных данных (включая тепловизионные и лазерные сканы), применение методов обучения без учителя для снижения зависимости от размеченных данных, а также развитие возможностей количественного измерения геометрических характеристик трещин в реальном времени. Особое значение имеет адаптация таких систем для мобильных платформ, в частности беспилотных летательных аппаратов (БПЛА), что позволит обеспечить безопасный, автоматизированный и надёжный мониторинг конструкций в труднодоступных или опасных зонах.
1. Flah, M. A. A comparative review of image processing-based crack detection techniques on civil engineering structures / M. A. Flah, M. Abdel Wahab, A. Alrowaily, M. L. Nehdi // Journal of Soft Computing in Civil Engineering. – 2020. – № 3. – Vol. 4. – P. 1–20. – DOI: https://doi.org/10.22115/scce.2021.287729.1325
2. Cha, Y. J. Deep learning-based crack damage detection using convolutional neural networks / Y. J. Cha, W. Choi, O. Büyüköztürk // Computer-Aided Civil and Infrastructure Engineering. – 2017. – № 5. – Vol. 32. – P. 361–378. –https://doi.org/10.1111/mice.12263
3. Mazni, M. I. An investigation into real-time surface crack classification and measurement for structural health monitoring using transfer learning convolutional neural networks and Otsu method / M. I. Mazni, N. Hamzah, Z. Ismail // Alexandria Engineering Journal. – 2024. – Vol. 86. – P. 111–125. https://doi.org/10.1016/j.aej.2024.02.052 EDN: https://elibrary.ru/SJJSBP
4. Golding, V. P. Crack Detection in Concrete Structures Using Deep Learning / V. P. Golding, Z. Gharineiat, H. S. Munawar, F. Ullah // Sustainability. – 2022. – Vol. 14. – P. 1–25. – DOIhttps://doi.org/10.3390/su14138117 EDN: https://elibrary.ru/SXHOMB
5. Munawar, H. S. Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages / H. S. Munawar, F. Ullah, A. Heravi, M. J. Thaheem, A. Maqsoom // Drones. – 2022. – № 5. – Vol. 6. – P. 1–23. –. https://doi.org/10.3390/ drones6010005 DOI: https://doi.org/10.3390/drones6010005; EDN: https://elibrary.ru/AUSSOX
6. Dorafshan, S. A comparative analysis of image thresholding methods for crack detection in concrete / S. Dorafshan, M. Maguire // Journal of Nondestructive Evaluation. – 2019. – № 3. – Vol. 38. – P. 1–11. –. https://doi.org/10.3390/infrastructures4020019 DOI: https://doi.org/10.1007/s10921-019-0600-y; EDN: https://elibrary.ru/UQIJCM
7. Yuan, Q. A Review of Computer Vision-Based Crack Detection Methods in Civil Infrastructure: Progress and Challenges / Q. Yuan, Y. Shi, M. Li // Remote Sensing. – 2024. – № 16. – Vol. 16. – P. 2910. –;https://doi.org/10.3390/rs16162910
8. Talab, A. M. A. Detection crack in image using Otsu method and multiple filtering in image processing techniques / A. M. A. Talab, Z. Huang, F. Xi, L. Haiming // Optik. – 2016. – № 3. – Vol. 127. – P. 1030–1033. – https://doi.org/10.1016/j.ijleo.2015.09.147
9. Hoang, N.-D. Detection of surface crack in building structures using image processing technique with an improved Otsu method for image thresholding / N.-D. Hoang // Advances in Civil Engineering. – 2018. – Vol. 2018. – P. 1–12. – DOIhttps://doi.org/10.1155/2018/9589861 DOI: https://doi.org/10.1155/2018/3924120
10. Chen, X. An Automatic Concrete Crack-Detection Method Fusing Point Clouds and Images Based on Improved Otsu's Algorithm / X. Chen, J. Li, S. Huang, H. Cui, P. Liu, Q. Sun // Sensors. – 2021. – № 5. – Vol. 21. – Pp:19 . https://doi.org/10.3390/s21051581
11. Nnolim, U. A. Automated crack segmentation via saturation channel thresholding, area classification and fusion of modified level set segmentation with Canny edge detection / U. A. Nnolim // Heliyon. – 2020. – Vol. 6, № 3. – P. 16. – DOI:https://doi.org/10.1016/j.heliyon.2020.e05748 EDN: https://elibrary.ru/OMBKZF
12. He, Y. YOLOv7-based crack detection and classification with Otsu pre-processing for structural health monitoring / Y. He, Z. Li, S. Wang, J. Chen // Engineering Structures. – 2023. – Vol. 274. – P. 115210.
13. Zou, Q. Deep Crack: Learning Hierarchical Convolutional Features for Crack Detection / Q. Zou, Z. Zhang, Q. Li, X. Qi, Q. Wang, S. Wang // IEEE Transactions on Image Processing. – 2020. – Vol. 28, № 3. – P. 1498–1512. – DOI:https://doi.org/10.1109/TIP.2018.2878966
14. Xie, X. Research on fast identification and segmentation algorithms for cracks of highway tunnels in complex environment / X. Xie, H. Wang, B. Zhou, J. Cai, F. Peng // Chinese Journal of Underground Space and Engineering. – 2022. – Vol. 18. – P. 1025–1034. –. Article ID: 1673-0836(2022)03-01025-09
15. Azouz, Z. Evolution of Crack Analysis in Structures Using Image Processing Technique: A Review / Z. Azouz, B. H. Asli, M. Khan // Electronics. – 2023. – Vol. 12. – P. 42. – https://doi.org/10.3390/electronics12183862 EDN: https://elibrary.ru/SIKDMP
16. Yuan, Q. A Review of Computer Vision-Based Crack Detection Methods in Civil Infrastructure: Progress and Challenges / Q. Yuan, Y. Shi, M. Li // Remote Sensing. – 2024. – Vol. 16. – P. 34. –. https://doi.org/10.3390/rs16162910
17. Munawar, H. S. Inspecting Buildings Using Drones and Computer Vision: A Machine Learning Approach to Detect Cracks and Damages / H. S. Munawar, F. Ullah, A. Heravi, M. J. Thaheem, A. Maqsoom // Drones. – 2022. – Vol. 6, № 5. – P. 23. –https://doi.org/10.3390/drones6010005 EDN: https://elibrary.ru/AUSSOX
18. Shalaby, Y. M. Condition assessment of concrete structures using automated crack detection method for different concrete surface types based on image processing / Y. M. Shalaby, M. Badawy, G. A. Ebrahim, A. M. Abdelalim // Construction and Building Materials. – 2024. – Vol. 1, № 81. – P. 16. – https://doi.org/10.1007/s44290-024-00089-5 EDN: https://elibrary.ru/JZPNCL
19. Kaveh, H. Recent advances in crack detection technologies for structures: a survey of 2022–2023 literature / H. Kaveh, R. Alhajj // Frontiers in Built Environment. – 2024. – Vol. 10. – P. 22. – https://doi.org/10.3389/fbuil.2024.1321634 EDN: https://elibrary.ru/TCAPIU
20. Tatsuro, Y. Crack Detection from a Concrete Surface Image Based on Semantic Segmentation Using Deep Learning / Y. Tatsuro, P. Chun // Journal of Advanced Concrete Technology. – 2024. – Vol. 18. – P. 493–504. – https://doi.org/10.3151/jact.18.493 EDN: https://elibrary.ru/LPTTDU
21. Zhou, Q. UAV vision detection method for crane surface cracks based on Faster R-CNN and image segmentation / Q. Zhou, S. Ding, G. Qing, J. Hu // Journal of Civil Structural Health Monitoring. – 2022. – Vol. 12. – P. 845–855. – https://doi.org/10.1007/s13349-022-00577-1 EDN: https://elibrary.ru/IEVOWK
22. Son, D. N. Deep Learning Based Crack Detection: A Survey / D. N. Son, T. ThaiSon, T. VanPhuc, H. J. Lee, J. Piran, P. LeVan // International Journal of Pavement Research and Technology. – 2023. – Vol. 16. – P. 943–967. – https://doi.org/10.1007/s42947-022-00172-z EDN: https://elibrary.ru/PGTCMQ
23. Zou, Q. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection / Q. Zou, Z. Zhang, Q. Li, X. Qi, Q. Wang, S. Wang // IEEE Transactions on Image Processing. – 2018. – Vol. 28. – P. 1498–1512. – DOI:https://doi.org/10.1109/TIP.2018.2878966
24. S Krishnan, S. R. Comparative analysis of deep learning models for crack detection in buildings / S. R. Krishnan, M. K. Karuppan, A. Khadidos, A. Khadidos, Sh. Tandon, B. Balusamy // Scientific Reports. – 2025. – Vol. 15. – P. 33. –https://doi.org/10.1038/s41598-025-85983-3 DOI: https://doi.org/10.1038/s41598-024-84647-y; EDN: https://elibrary.ru/NHLEVT
25. Wu, J. Tunnel crack detection method and crack image processing algorithm based on improved Retinex and deep learning / J. Wu, X. Zhang // Sensors. – 2023. – Vol. 23, № 22. – P. 16. – https://doi.org/10.3390/s23229140 EDN: https://elibrary.ru/MWGENT
26. Paramanandham, K. Vision based crack detection in concrete structures using cutting-edge deep learning techniques / K. Paramanandham [et al.] // Construction and Building Materials. – 2022. – Vol. 23. – https://doi.org/10.3390/s23229140
27. Zhang, X. Highway Crack Material Detection Algorithm Based on Digital Image Processing Technology // Journal of Physics: Conference Series. – 2023. – № 2425. – P. 8. – doihttps://doi.org/10.1088/1742-6596/2425/1/012067 EDN: https://elibrary.ru/XFKCEE
28. Salunkhe, A. A. Progress and Trends in Image Processing Applications in Civil Engineering: Opportunities and Challenges / A. A. Salunkhe, R. Gobinath, S. Vinay, L. Joseph // Advances in Civil Engineering. – 2022. – Vol. 1. – P. 17. – https://doi.org/10.1155/2022/6400254 EDN: https://elibrary.ru/MXVZMN
29. Chowdhury, A. M. A Comprehensive Analysis of the Integration of Deep Learning Models in Concrete Research from a Structural Health Perspective / A. M. Chowdhury, R. Kaiser // Construction Materials. – 2024. – Vol. 4. – P. 72–90. – https://doi.org/https://doi.org/10.3390/constrmater4010005 EDN: https://elibrary.ru/LEGDPA
30. Ashraf, A. Machine learning-based pavement crack detection, classification, and characterization: a review / A. Ashraf, A. Sophian, A. A. Shafie, T. S. Gunawan, N. N. Ismail // Bulletin of Electrical Engineering and Informatics. – 2023. – Vol. 12, № 6. – P. 19. –DOI:https://doi.org/10.11591/eei.v12i6.5345 EDN: https://elibrary.ru/DKHGYO
31. Inam, H. Smart and Automated Infrastructure Management: A Deep Learning Approach for Crack Detection in Bridge Images / H. Inam, N. Ul Islam, M. Akram, F. Ullah // Sustainability. – 2023. – Vol. 15. – P. 35. –. https://doi.org/10.3390/ su15031866. DOI: https://doi.org/10.3390/su15010035; EDN: https://elibrary.ru/SZRUDE
